Kafka Notes
1. 前言
Kafka是现在业界选择比较多的一种消息队列解决方案。我这里主要也是选Kafka作为消息队列这块需求的解决方案。下面的技术调研会先从消息队列本身开始,然后做一个横向比较,最后再聚焦到Kafka本身上。
调研用的Kafka版本为:
2.2.0官方文档:
- 官方介绍:Introduction
- 官方新手入门:Quickstart
- 官方应用场景介绍:Use cases
- 官方文档:Documentation
- Docker Hub:wurstmeister/kafka
一本中文手册,版本较老,看看范例代码尚可:Apache kafka中文手册。
2. 消息队列
在聊Kafka之前,其实更需要关注下消息队列本身。什么需求下需要使用消息队列、消息队列的功能点有哪些、消息队列的模式有哪些、消息队列的实现难点有哪些,等等。如果什么都不了解,那技术选型就无从谈起了,也没办法理解为什么消息队列要做好是非常困难的一件事情。展开了说,也就没办法举一反三,理解其他软件系统的设计精髓了。
下面会简单列举下消息队列的一系列知识点,细节内容这里就不展开了,篇幅太大。
消息队列的需求:
- 解耦
- 最终一致性
- 广播
- 错峰与流控
消息队列的模型:
- 点对点:单生产、单队列、单消费
- 生产者消费者模型:多生产、单队列、多消费
- 发布订阅模型:根据topic分队列,多生产、多队列、多消费
消息队列的投递模式:
- Push:消息队列主动推送(e.g RocketMQ可选)
- Pull:消费者主动抓取(e.g Kafka)
消息队列的性能指标:
- 吞吐量(Throughput)
- 响应时间(Latency)
消息队列的投递策略:
- 最多一次(At most Once):消息可能会丢,但绝不会重复传输
- 最少一次(At least Once):消息绝不会丢,但可能会重复传输
- 仅有一次(Exactly Once):每条消息肯定会被传输一次且仅传输一次
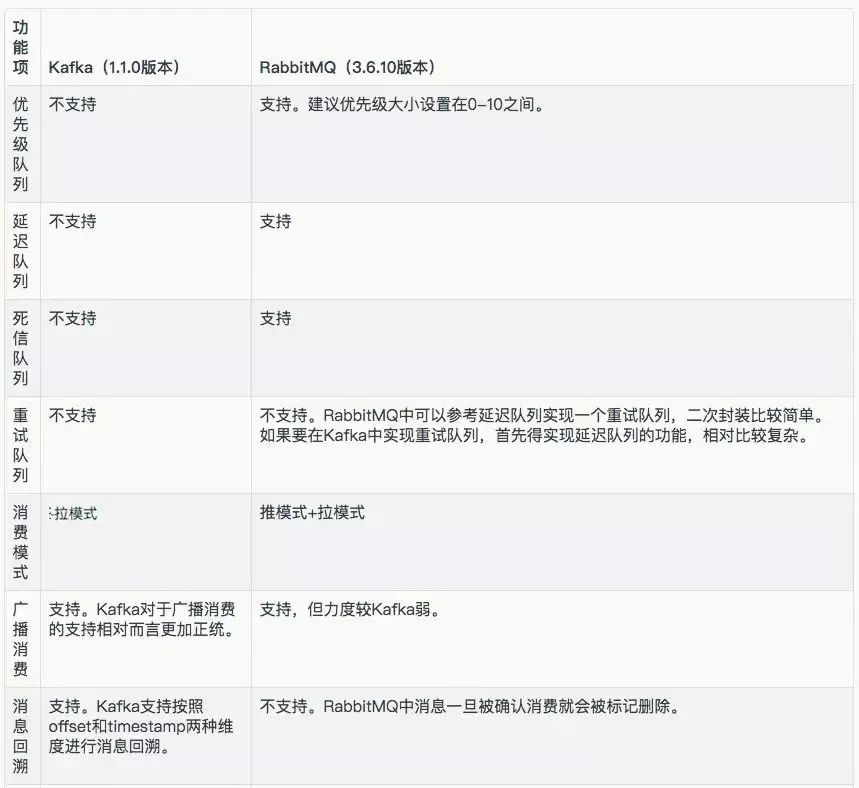
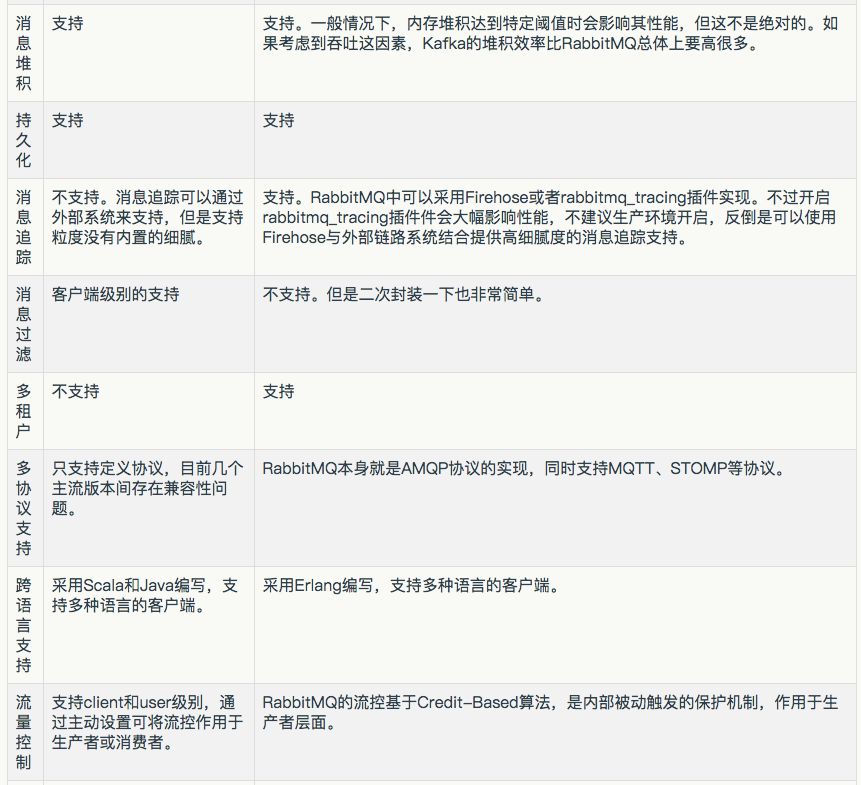
消息队列的功能性:
- 优先级队列
- 延迟队列
- 死信队列
- 重试队列
- 消息回溯
- 消息堆积 + 持久化
- 消息追踪
- 消息过滤
- 多租户
- 多协议支持
- 跨语言支持
- 流量控制
- 可靠投递
- 消费确认
- 消息顺序性
- 安全机制
- 消息幂等性
- 事务性消息
几篇值得一读的博文:
一篇通论形式的消息队列设计博文,讲解了一些消息队列通用的知识点,值得一读。
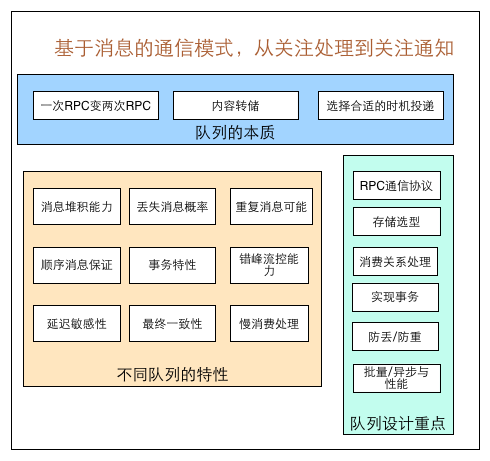
本质上也是一篇对于消息队列进行设计和讲解的博文,但结合了美团公司内部的实际项目经验,对于大型系统的设计者有更好的贴近应用场景的指导作用。
接上一篇的博文,更多讲到了性能和高级功能相关的实现以及性能的优化。
排版比较粗糙,但内容非常不错。以贴近项目经验的内容讲解了RabbitMQ和Kafka的:
- 高可用性
- 消息幂等性
- 消息可靠性
- 消息顺序性
- 消息积压场景处理
3. 消息队列选型比较
消息队列的选型一直都是比较困难的,业界现在比较主流的选择有:ActiveMQ、RabbitMQ、Kafka、RocketMQ、ZeroMQ 这几种。
有几篇不错的博文可以看下:
消息中间件选型分析:从 Kafka 与 RabbitMQ 的对比看全局
这篇时间还算比较接近2018年5月2日,主要是以Kafka和RabbitMQ为范例进行了消息队列选型的要点讲解。虽然讲解的时候使用了Kafka以及RabbitMQ作为范例,但实际上讲解的是通用的消息队列选型要点。结合本文上一节所讲到的消息队列的一系列知识点,应该能有更深刻的理解。

滴滴出行基于 RocketMQ 构建企业级消息队列服务的实践
这篇时间稍微有点久,文中提到的Kafka版本还是0.8左右的(虽然文章的发布时间倒是不久之前),所以文中提到的性能指标之类的仅可作为参考。这篇文章是对Kafka和RocketMQ做的一个技术选型比较,文章中有相当多的性能指标比较,并结合滴滴公司的实际情况讲解了下消息队列系统进行替换时候所做的Migration工作,非常有借鉴价值。此外,文中还有一小节讲解了下RocketMQ使用的经验。
Why is Kafka pull-based instead of push-based?
为什么Kafka消息队列使用的是Pull投递模式。
Modern Open Source Messaging: NATS, RabbitMQ, Apache Kafka, hmbdc, Synapse, NSQ and Pulsar
老外写的一篇,提到了不少国内较少提到的开源项目,可以作为参考。
3.1 Apache Pulsar
关于Kafka和后起新秀Pulsar的横向比较,可以看:
- 比拼Kafka,大数据分析新秀Pulsar到底好在哪
- High performance messaging with Apache Pulsar
- 选择 Pulsar 而不是 Kafka 的 7 大理由
大略的要点:
- 功能性上Pulsar要比Kafka更好,且这是在不牺牲性能的前提下的,就更加难能可贵
- 解决了Kafka单partition只能单consumer消费的问题
- 将Broker和存储解耦,做到更好的错误恢复,在Broker宕机之后可以做到无损耗恢复
- 存储方面的功能交付给Bookie,更细粒度的存储,更好的错误恢复和同步性能
4. Kafka架构
4.1 概念
老样子从基本的概念开始梳理:
broker:kafka集群中的任意一台提供服务的物理服务器即被称为brokertopic:消息队列的一个队列,一般做架构的时候按需求将不同的消息分别派送到不同的管道里,而其中的任意一个管道在kafka里就是一个topicpartition:topic下的概念,任意一个topic根据启动时的设定,会分成多个partition,而每个partition会由集群安排在某一台物理机broker上,以此做到集群的横向扩展offset:partition下的概念,topic被分为很多partition,而每个partition则都会存储消息,每个partition存储的消息都是从0开始进行标号,而这个每条消息一个的标号,即为offset;可以理解为消息在partition里的唯一id;不同的partition都是从0开始标号,因此offset只对其自身的partition生效,不可混用replica:某个partition的完整备份(在接收写入请求时数据可能会落后于leader),用在集群的高可用服务上,同时也可以提供partition读操作的负载均衡producer:向topic里输入消息数据的角色consumer:从topic里消费消息数据的角色consumer group:可扩展且具有容错性的consumer机制,多个consumer共享一个group id,组内的所有consumer一起来消费topic的所有partition;但一个partition仍旧只能由一个consumer进行消费;主要是为了解决consumer和partition配对balance的问题,将consumer做成组由集群自动进行平衡并分配到partition
关于consumer group,更多的可以看:Kafka消费组(consumer group)。
4.2 集群 {#ID_CLUSTER}
一张图基本上就能说明问题:
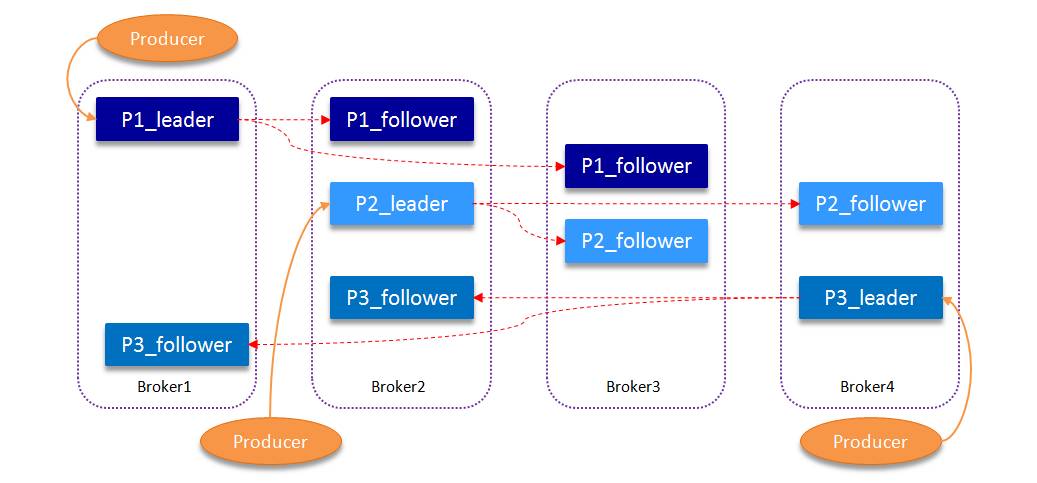
- kafka集群由多台broker(物理机)组成
- 图示中有
四台broker - 每个topic会根据配置,生成固定数量的partition,均匀分配到物理机上
- 图示中的topic被分成了
3个partition:P1_leader(broker1)、P2_leader(broker2)、P3_leader(broker4) - 每个partition根据配置,会拥有固定数量的follower(replica),分别分配到各个物理机上
- 图示中即:
P1_follower(broker2、broker3)、P2_follower(broker3、broker4)、P3_follower(broker1、broker2) - 当有broker宕机的时候:
- 丢失的follower会由集群重新寻找节点进行备份
恢复 - 丢失的leader会由集群自现存的follower中
选举产生,成为新的leader
- 丢失的follower会由集群重新寻找节点进行备份
4.3 分布式痛点(offset)
Kafka在分布式解决方案上也有痛点,主要是每个partition的offset问题。
为了性能,kafka将一个partition视作一个管道,拥有一个从0开始的offset。这样做的好处就是不再需要在每一个消息体上做metadata存放该消息是否被消费掉等信息,而是通过partition的offset来标记整个管道中的消息被消费到了哪里。消息体更简单,流程上也更简单,不会出现乱序的消费情况。但也正是因为这种设计,导致每个partition无法由多个consumer并发消费,每个partition绑定只能同时允许一个consumer消费。
因此,从机制上来说,kafka并不适合用来做consumer重消耗(CPU)类型的消息通道。虽然partition可以做很多,极端点来说可以做到和consumer实际需求1:1的配比,但超过适配当前需求的partition数量设置也会造成吞吐量的下降(参见:6.2.4 场景4)。
consumer和partition在进行消息是否被消费掉的确认行为上,有两种方式:
- 自动提交:
- 设置
enable.auto.commit=true - 更新的频率根据参数
auto.commit.interval.ms来定,这种方式被称为at most once - consumer fetch到消息后,partition就会更新offset,无论是否消费成功
- 设置
- 手动提交:
- 设置
enable.auto.commit=false - 这种方式被称为
at least once - consumer fetch到消息后,必须在消费成功后调用方法
consumer.commitSync(),手动通知partition更新offset - 如果消费失败,则offset不会更新,此条消息会被重复消费一次
- 设置
关于partition和consumer之间的关系,更多可以看下:
How multiple consumer group consumers work across partition on the same topic in Kafka?
If you want to have more consumers than partitions and still have performance enhancement and process only each message once, then you should increase the number of partitions in the topics so that there are at least as many partitions as consumers. Often topics are created with 2 times as many partitions needed to start, just so more consumers can be added later if needed without having to repartition the topic.
1个partition只能被同组的一个consumer消费,同组的consumer则起到均衡效果
以及自动提交相关:Understanding the ‘enable.auto.commit’ Kafka Consumer property。
4.4 临时消费压力应急
如果因某些原因,之前设计的partition分片数量不够导致能够上工的consumer数量不够,且consumer的消费速率跟不上的时候,就会发生消息堆积。如果堆积的情况比较严重的话,就需要程序介入处理。
思路如下:
- 老的partition以及老的topic肯定不能动,就算重新进行repartition整个集群重新平衡耗费的时间也是难以忍受的
- 创建新的topic
- 将新的topic的partition设到consumer消费速率能跟上的数量
- 将新的consumer部署上去,消费新设置的topic和partition
- 将老的topic以及partition上挂载的consumer全部停止
- 在老的topic以及partition上挂载临时consumer,这批consumer不做任何逻辑处理,只是将老的topic内的消息全部读取出来,并输入到新的topic里
这样老的topic里的消息就全部分发到新的topic里了,且新的topic的partition数量很高,可以挂载很多consumer处理堆积的消息。
5. Kafka监控 & 高可用
5.1 监控
监控方面,datadog的几篇文章非常不错,值得一读,不过版本有点老了,文章是2016年的:
详细的指标列表及其含义,可以看这篇:Monitoring Kafka。
5.1.1 Exporter & Grafana Dashboard
Prometheus的Exporter分为两块:
- 以Java为runtime的通用监控:prometheus/jmx_exporter
- 代码:prometheus/jmx_exporter
- 镜像:sscaling/jmx-prometheus-exporter
- sscaling/jmx-prometheus-exporter:0.11.0
- Dashboard:
- Kafka Overview,这个dashboard相当老了,一直没有更新,而且仅只有6个Panel,和kafka有关的panel更只有3个,基本没什么用;但未能找到更近一点的kafka专用dashboard
- JVM dashboard,jmx通用dashboard,看上去更好点;但这个dashboard变量设置的是job,所以在设置Prometheus的时候就需要将多个kafka的数据采集到同一个job里,而不是分开
- JMX exporter prometheus,另一款jmx通用dashboard;这个dashboard是为了在k8s中使用而特化的,也不够灵活
- 列在Prometheus官方列表上的第三方Exporter:danielqsj/kafka_exporter
- 代码:danielqsj/kafka_exporter
- 镜像:danielqsj/kafka-exporter
- danielqsj/kafka-exporter:v1.2.0
- Dashboard:Kafka Exporter Overview
- 该Exporter使用Golang编写,更专注于部分Kafka业务相关metrics,对于核心的Java runtime metrics仍旧需要jmx_exporter
此外,还有一个confluent公司的grafana dashboard配置,没找到对应的labs dashboard地址,但该配置文件本身也有参考价值:kafka-confluent-platform/grafana-kafka-dashboard.json。
可参考的jmx_exporter配置:
5.1.2 Docker实践
实际运行范例参见:
- dist-system-practice/conf/dev/kafka-cluster.yaml
- dist-system-practice/conf/dev/prometheus-cluster.yaml
- dist-system-practice/vendors/kafka/
- dist-system-practice/vendors/prometheus/grafana/dashboards/
Exporter方面,jmx_exporter和kafka_exporter同时使用,两者侧重不同。jmx_exporter主要用来进行JVM监控,针对java runtime自身的状态进行监控,而kafka_exporter则针对kafka运行状况进行监控(其实只要不怕麻烦自己处理dashboard,则jmx_exporter就完全足够了)。
jmx_exporter的部署有两种选择,一是独立的容器进行部署,好处是可观察性强,且不会对kafka容器造成影响,缺点是部署更繁杂,配置内容更多;二是修改kafka容器,添加几项配置项,就可以直接在kafka容器内启动一个java进程,进行metrics输出。这里实践使用的是第二种方法,配置修改如下:
kafka_1:
image: ...
...
volumes:
- /private/tmp/jmx_prometheus_javaagent-0.9.jar:/usr/local/bin/jmx_prometheus_javaagent-0.9.jar
- /private/tmp/jmx-kafka-2_0_0.yaml:/etc/jmx-exporter/jmx-kafka-2_0_0.yaml
- ...
networks:
...
ports:
- "19092:9092" # client port
- "17071:7071" # jmx prometheus metrics
expose:
- "9092" # client port
- "9093" # internal traffic
- "9991" # jmx
- "7071" # jmx prometheus metrics
restart: "always"
logging:
<<: *KAFKA_LOGGING_DEFAULTS
environment:
...
JMX_PORT: 9991
KAFKA_OPTS: "-javaagent:/usr/local/bin/jmx_prometheus_javaagent-0.9.jar=7071:/etc/jmx-exporter/jmx-kafka-2_0_0.yaml"
<<: *KAFKA_ENV_DEFAULTSJMX_PORT告知kafka在启动的时候需要一并启动jmx,KAFKA_OPTS告知kafka在启动时一并需要启动jmx_exporter,而这个exporter的jar包以及配置文件则是通过bind mount放入容器内的。
配置文件主要来自于:kafka-grafana/jmx-exporter/kafka-2_0_0.yml。此外,因为使用通用jmx dashboard:JVM dashboard来进行数据展示,该配置文件中也放入了部分这个dashboard要求的数据转换规则:
lowercaseOutputLabelNames: true
rules:
# JMX common
- pattern: 'java.lang<type=OperatingSystem><>(committed_virtual_memory|free_physical_memory|free_swap_space|total_physical_memory|total_swap_space)_size:'
name: os_$1_bytes
type: GAUGE
attrNameSnakeCase: true
- pattern: 'java.lang<type=OperatingSystem><>((?!process_cpu_time)\w+):'
name: os_$1
type: GAUGE
attrNameSnakeCase: true
...此外还有prometheus集群采集添加以及grafana dashboard导入,都是常规操作,就不多说了。
5.2 高可用
在之前的4.2 集群中,已经介绍过了Kafka的集群模式,可以看到Kafka天然就是分布式的,而且在设计之初就考虑到了集群的高可用。本文之前章节内关于集群的内容偏简单了,只介绍了大致的设计。如有需要更深入了解分布式和高可用的细节,则可以阅读唯品会的:Kafka 数据可靠性深度解读,这篇讲解非常透彻,基本上可以当经典来看了。
Kafka的高可用配置,有几个配置项控制了集群的安全程度。这里需要记住一点,整个集群越安全集群的吞吐量就越低,这是等价交换的,不可能不付出任何代价就获得数据的安全性。唯品会的文章讲解的细节非常多,但我们真正执行操作的时候可以只知其然,懂得哪几个配置项需要操作即可:
- topic:
replication.factor:每个partition会拥有多少个replicamin.insync.replicas:partition的leader节点要求当前在线的replica节点的数量,如果实际在线数量少于这个数值,客户端的请求会被拒绝:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required
- broker:
unclean.leader.election.enable:是否允许out-of-sync replica成为leader
- producer:
- producer.type:消息生产者提交消息到kafka服务器的时候的模式,可选:sync或async
sync拥有很好的安全性async拥有更高的吞吐量,可以批量进行消息发送
- request.required.acks:kafka服务器在收到消息之后何时对生产者进行完成反馈
1(默认):partition的leader节点收取完成即反馈,如果在follower同步数据之前leader宕机则数据丢失0:producer不等待kafka服务器反馈即直接进行后续发送,拥有最高的吞吐量以及最低的安全性-1:partition的所有节点包括了leader以及所有的follower全部都确认数据同步完成再反馈,最高的安全性以及最低的吞吐量
- producer.type:消息生产者提交消息到kafka服务器的时候的模式,可选:sync或async
要保证数据写入到Kafka是安全的,高可靠的,需要如下配置:
- topic:
- replication.factor>=3:即副本数至少是3个
- 2<=min.insync.replicas<=replication.factor:要求每个partition leader的在线replica数量最少保持2个
- broker:
- unclean.leader.election.enable=false:不允许out-of-sync replica成为leader
- producer:
- request.required.acks=-1(all):producer发送的消息请求必须让partition所有的replica都同步完毕才会返回成功
- producer.type=sync:producer发送的消息以同步方式发送,即在写入成功之前,producer必须等待
6. Kafka Benchmark
这里的内容全部是转载自唯品会的:Kafka 数据可靠性深度解读。网上的资料很容易失效,因此在这里做下转载。
Benchmark的Kafka版本是:
0.10.1.06.1 测试环境
Kafka broker 用到了 4 台机器,分别为 broker[0/1/2/3] 配置如下:
- CPU: 24core/2.6GHZ
- Memory: 62G
- Network: 4000Mb
- OS/kernel: CentOs release 6.6 (Final)
- Disk: 1089G
- Kafka 版本:0.10.1.0
broker 端 JVM 参数设置:
-Xmx8G -Xms8G -server -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true -Xloggc:/apps/service/kafka/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=9999客户端机器配置:
- CPU: 24core/2.6GHZ
- Memory: 3G
- Network: 1000Mb
- OS/kernel: CentOs release 6.3 (Final)
- Disk: 240G
6.2 不同场景测试
6.2.1 场景1
测试不同的副本数、min.insync.replicas 策略以及 request.required.acks 策略(以下简称 acks 策略)对于发送速度(TPS)的影响。
具体配置:
- 一个 producer
- 发送方式为 sync
- 消息体大小为 1kB
- partition 数为 12
- 副本数为:1/2/4
- min.insync.replicas 分别为 1/2/4
- acks 分别为 -1(all)/1/0
具体测试数据如下表(min.insync.replicas 只在 acks=-1 时有效):
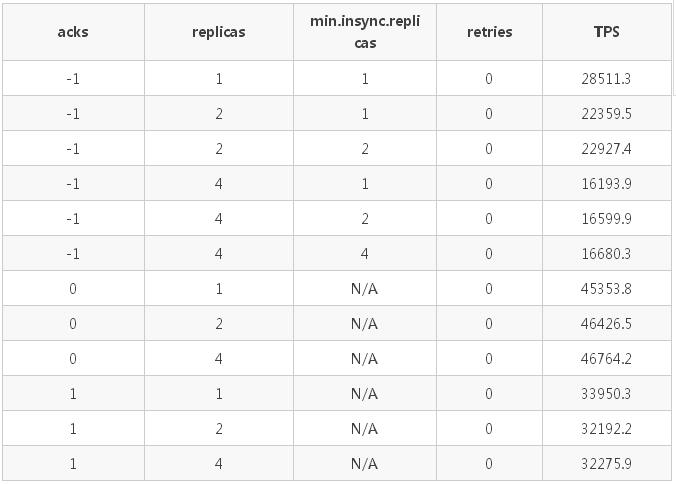
测试结果分析:
- 客户端的 acks 策略对发送的 TPS 有较大的影响,TPS:acks_0 > acks_1 > ack_-1;
- 副本数越高,TPS 越低;副本数一致时,min.insync.replicas 不影响 TPS;
- acks=0/1 时,TPS 与 min.insync.replicas 参数以及副本数无关,仅受 acks 策略的影响。
下面将 partition 的个数设置为 1,来进一步确认下不同的 acks 策略、不同的 min.insync.replicas 策略以及不同的副本数对于发送速度的影响,详细请看情景 2 和情景 3。
6.2.2 场景2
在 partition 个数固定为 1,测试不同的副本数和 min.insync.replicas 策略对发送速度的影响。
具体配置:
- 一个 producer
- 发送方式为 sync
- 消息体大小为 1kB
- producer 端 acks=-1(all)
- 变换副本数:2/3/4
- min.insync.replicas 设置为:1/2/4
测试结果如下:
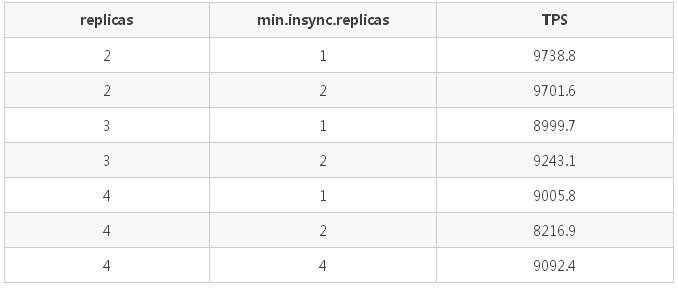
测试结果分析:
副本数越高,TPS 越低(这点与场景 1 的测试结论吻合),但是当 partition 数为 1 时差距甚微。min.insync.replicas 不影响 TPS。
6.2.3 场景3
在 partition 个数固定为 1,测试不同的 acks 策略和副本数对发送速度的影响。
具体配置:
- 一个 producer
- 发送方式为 sync
- 消息体大小为 1kB
- min.insync.replicas=1
- topic 副本数为:1/2/4
- acks: 0/1/-1
测试结果如下:
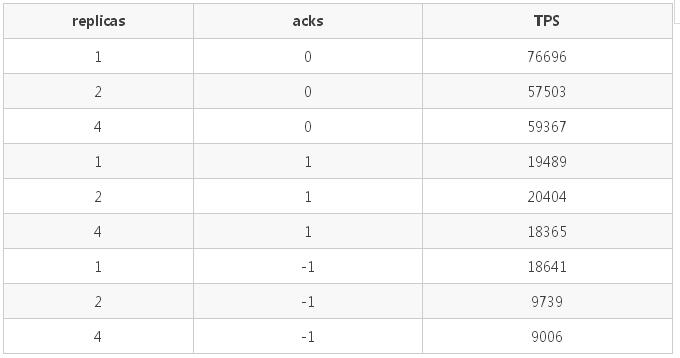
测试结果分析(与情景 1 一致):
- 副本数越多,TPS 越低;
- 客户端的 acks 策略对发送的 TPS 有较大的影响,TPS:acks_0 > acks_1 > ack_-1。
6.2.4 场景4 {#ID_BENCHMARK_SCEN4}
测试不同 partition 数对发送速率的影响
具体配置:
- 一个 producer
- 消息体大小为 1KB
- 发送方式为 sync
- topic 副本数为 2
- min.insync.replicas=2
- acks=-1
- partition 数量设置为 1/2/4/8/12
测试结果:
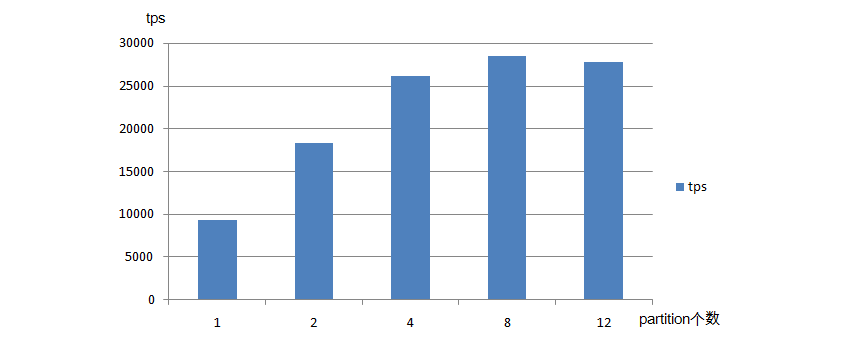
测试结果分析:
partition 的不同会影响 TPS,随着 partition 的个数的增长 TPS 会有所增长,但并不是一直成正比关系,到达一定临界值时,partition 数量的增加反而会使 TPS 略微降低。
6.2.5 场景5
通过将集群中部分 broker 设置成不可服务状态,测试对客户端以及消息落盘的影响。
具体配置:
- 一个 producer
- 消息体大小 1KB
- 发送方式为 sync
- topic 副本数为 4
- min.insync.replicas 设置为 2
- acks=-1
- retries=0/100000000
- partition 数为 12
具体测试数据如下表:
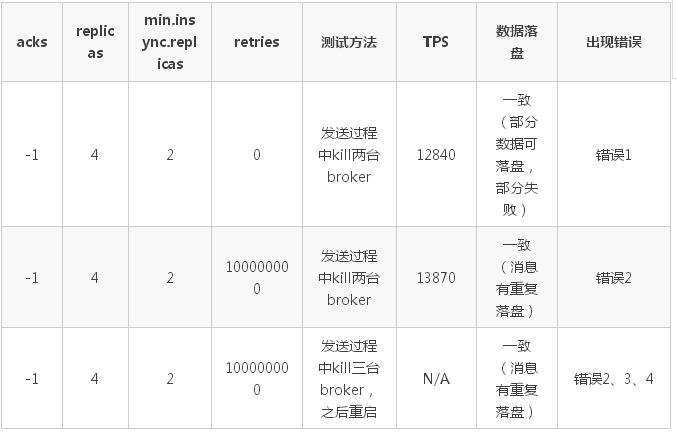
出错信息:
- 错误 1:客户端返回异常,部分数据可落盘,部分失败:org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
- 错误 2:[WARN]internals.Sender - Got error produce response with correlation id 19369 on topic-partition default_channel_replicas_4_1-3, retrying (999999999 attempts left). Error: NETWORK_EXCEPTION
- 错误 3: [WARN]internals.Sender - Got error produce response with correlation id 77890 on topic-partition default_channel_replicas_4_1-8, retrying (999999859 attempts left). Error: NOT_ENOUGH_REPLICAS
- 错误 4: [WARN]internals.Sender - Got error produce response with correlation id 77705 on topic-partition default_channel_replicas_4_1-3, retrying (999999999 attempts left). Error: NOT_ENOUGH_REPLICAS_AFTER_APPEND
测试结果分析:
- kill 两台 broker 后,客户端可以继续发送。broker 减少后,partition 的 leader 分布在剩余的两台 broker 上,造成了 TPS 的减小;
- kill 三台 broker 后,客户端无法继续发送。Kafka 的自动重试功能开始起作用,当大于等于 min.insync.replicas 数量的 broker 恢复后,可以继续发送;
- 当 retries 不为 0 时,消息有重复落盘;客户端成功返回的消息都成功落盘,异常时部分消息可以落盘。
6.2.6 场景6
测试单个 producer 的发送延迟,以及端到端的延迟。
具体配置:
- 一个 producer
- 消息体大小 1KB
- 发送方式为 sync
- topic 副本数为 4
- min.insync.replicas 设置为 2
- acks=-1
- partition 数为 12
测试数据及结果(单位为 ms):
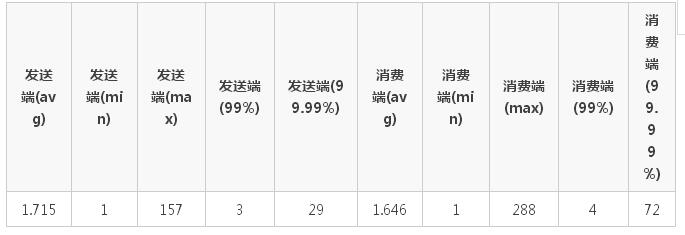
6.3 各场景测试总结
- 当 acks=-1 时,Kafka 发送端的 TPS 受限于 topic 的副本数量(ISR 中),副本越多 TPS 越低;
- acks=0 时,TPS 最高,其次为 1,最差为 -1,即 TPS:acks_0 > acks_1 > ack_-1;
- min.insync.replicas 参数不影响 TPS;
- partition 的不同会影响 TPS,随着 partition 的个数的增长 TPS 会有所增长,但并不是一直成正比关系,到达一定临界值时,partition 数量的增加反而会使 TPS 略微降低;
- Kafka 在 acks=-1,min.insync.replicas>=1 时,具有高可靠性,所有成功返回的消息都可以落盘。
7. Kafka使用范例
实验使用的还是下载下来的Kafka,版本如头部申明的是2.2.0。范例代码可以在Github查看:dist-system-practice/experiment/kafka/。
8. 在Docker内部署集群
一般来说部署一个以上的docker容器组成集群,可以使用bash脚本的方法,自己编写命令一个个启动,但更好的方法是使用docker-compose命令,读取配置文件,将整个集群按设定的模式启动起来。可运行范例可以查看:dist-system-practice/conf/dev/kafka-cluster.yaml。
启动脚本:dist-system-practice/bash/dev/docker_kafka.sh。
主要有几个点需要注意下。
8.1 重要配置项
services:
kafka_1:
image: "wurstmeister/kafka:2.12-2.2.0" # 一定需要
hostname: "kafka_1"
container_name: "kafka_1" # 使用这个名字来让同network的其他服务进行访问
depends_on:
- "zookeeper" # 保证启动先后顺序
volumes:
- /private/tmp/jmx_prometheus_javaagent-0.9.jar:/usr/local/bin/jmx_prometheus_javaagent-0.9.jar
- /private/tmp/jmx-kafka-2_0_0.yaml:/etc/jmx-exporter/jmx-kafka-2_0_0.yaml
- kafka_vol_1:/tmp/kafka/data
networks:
- "net"
ports:
- "19092:9092" # client port # 保证非同一network的其他服务也能访问,但这么做要求每个kafka service都监听不同的端口,相互不能冲突
- "17071:7071" # jmx prometheus metrics
expose:
- "9092" # client port
- "9093" # internal traffic # kafka集群内部流量走的端口号
- "9991" # jmx # jmx进程本身监听的地址,提供给jmx_exporter连接用
- "7071" # jmx prometheus metrics # jmx_exporter监听的地址,提供给prometheus抓取metrics
restart: "always"
logging:
driver: "json-file" # 日志输出以json格式,容易让聚合工具使用
options:
max-size: "512m" # 保证日志最大尺寸不会过大占用过多系统磁盘
environment:
KAFKA_LISTENERS: "INSIDE://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092" # kafka的实际监听地址,一般不是0.0.0.0就是容器名
KAFKA_ADVERTISED_LISTENERS: "INSIDE://kafka_1:9093,OUTSIDE://127.0.0.1:19092" # kafka发布到zookeeper,让客户端获取并凭之连接kafka的地址,一定需要是客户端能访问到的地址,INSIDE部分供集群内部流量使用,OUTSIDE供客户端使用
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT" # 明确内部外部的通讯协议
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE # 告诉kafka集群上面的INSIDE和OUTSIDE配置哪个才是供集群内部流量使用的,按语义一般是INSIDE
KAFKA_BROKER_ID: 0 # 必须每个kafka broker单独一个,不可重复
JMX_PORT: 9991 # jmx监听的地址
KAFKA_OPTS: "-javaagent:/usr/local/bin/jmx_prometheus_javaagent-0.9.jar=7071:/etc/jmx-exporter/jmx-kafka-2_0_0.yaml" # kafka在启动时一并会给予启动
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181" # 告知kafka zookeeper的地址
KAFKA_LOG_DIRS: "/tmp/kafka-logs" # kafka实际的数据存放位置,推荐使用volume进行该地址的local映射
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 # kafka内部用来保存topic的offset的数据,其replication数量
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 # kafka内部用来保存transaction state log的数据,其replication数量
KAFKA_MIN_INSYNC_REPLICAS: 1 # partition的leader节点要求当前在线的replica节点的数量关于LISTENER相关的几个配置(用于集群访问)更多的可以看下:8.2 对容器外应用提供服务。
参见:
8.2 对容器外应用提供服务 {#DOCKER_OUT_NET}
在docker中部署集群有一个比较大的问题就是容器内部和外部的网络访问地址是隔离的,而kafka集群部分节点的相互发现是根据配置:KAFKA_ADVERTISED_LISTENERS来进行通知的。
如果该配置内的地址填写的是127.0.0.1这样的回环地址或容器外的IP,那么容器内各kafka节点之间的通讯就会有问题(因为容器内各节点拿到的配置地址都是容器外的IP)。而如果将该配置内的地址都配置成docker容器的名字,那么在容器内部的流量是没问题了,但外部访问kafka服务的应用程序拿到的地址则是容器的名字,就没法访问了。
所以对于需要向容器外部环境的应用提供服务的情况来说,需要做好几项配置的调整(这里说的配置都是kafka的配置,不涉及到zookeeper的配置,事实上集群部署的配置中zookeeper相关的内容非常简单):
KAFKA_LISTENERS: "INSIDE://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092"
KAFKA_ADVERTISED_LISTENERS: "INSIDE://kafka_1:9093,OUTSIDE://127.0.0.1:19092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDEkafka的配置中,现在可以将内部流量和外部流量的监听地址分离开来,在配置LISTENERS相关的配置时,使用,将INSIDE和OUTSIDE隔离开来即可。一般来说,INSIDE的地址会配置成当前节点的容器名,或者就直接设置成0.0.0.0。而OUTSIDE则根据自身需求设置即可,这里的范例是给本机开发测试用,因此设置的是127.0.0.1。
KAFKA_INTER_BROKER_LISTENER_NAME配置项则是告诉kafka,集群各broker节点之间是使用INSIDE还是OUTSIDE配置作为集群内部流量的通讯地址。此外需要注意的是,该配置的INSIDE和OUTSIDE监听的端口是不可以重复的,因为实际上kafka就是开了两个端口都在监听。
一般第一次在本地设置集群进行开发和调试的时候,这里是个大坑,非常麻烦。配置不正确就会发现kafka完全无法通讯。
8.3 docker-compose scale
一般来说,kafka service的配置不适合在配置文件中只设置一份,然后使用docker-compose scale的方法进行横向扩展。
适用scale的场景只有完全无状态,且各个节点之间的配置完全相同的情况,而kafka各节点一般最好设置自身的container_name,然后在监听地址中使用正确的容器名作为地址,来进行相互通讯。
8.4 yaml配置重用
因为无法使用scale的缘故,必须手写大量的kafka service节点yaml配置,这倒也不算是大问题。关键的问题在于有大量重复的配置项,如果后面要修改,就很麻烦,怕漏改或者改错。
因此最好的方法是使用yaml的配置重用,来设置共通的配置,然后像变量一样重用。这可以参见我之前提到的范例配置文件:
x-kafka-environment-defaults: &KAFKA_ENV_DEFAULTS
...
# 在这里放默认的配置
...
services:
kafka_1:
...
environment:
...
<<: *KAFKA_ENV_DEFAULTS # 这样就把作为变量的配置全部导入到这个点上了8.4 相关参考
- Building Apache Kafka cluster using docker-compose and VirtualBox
- Deploying a Kafka broker in a Docker container
9. 写性能与安全性
在进行测试的过程中,发现写入的速度比较慢,基本上每次写入在kafka集群这边会耗时1秒多,完全不能接受了。之前的博文中也提到了,集群安全性和写入性能是反比的,主要有几项因素:
- producer的写入模式:同步、异步
- 异步拥有最佳的性能,但安全性极差
- 同步性能很差,但安全性有保证
- acks写入的集群同步模式:-1完全同步、0完全不等待同步、1Leader节点同步
- 0拥有最佳性能,最低的安全性
- -1拥有最佳性能,但性能最低
- 1则比较均衡
- partition数量:acks如果为-1,则需要同步所有节点,partition数量越多则性能越低
后续进行了一些研究和测试。
集群共3个broker,topic分片如下:
Topic:work-topic PartitionCount:3 ReplicationFactor:3 Configs:
Topic: work-topic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: work-topic Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: work-topic Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2查了下官方配置,producer.acks这个现在放在3.3 Producer Configs里,命名为acks(链接)。需要注意的是,这一项配置并不是服务端的配置项,而是连接上来的客户端producer所进行的设置,是否acks根据客户端producer的要求而变动。这很反直觉,我一开始一直都以为这是服务端的配置项,没想到居然是客户端的。
acks在kafka-go的使用,可以查看注释:kafka-go/writer.go,默认是-1,也就是最安全但最慢的那种。
此外,写入模式是同步还是异步也是客户端设置,见:kafka-go/writer.go。
在上面提到的几项要素中,集群规模和partition数量之类都是业务要求,一般不会轻易变动,所以测试主要是实验在不同写入模式和acks情况下的性能变动。
测试:
同步 -1 1秒+
同步 1 1秒+
同步 0 1秒+
异步 -1 0.2ms 几乎瞬间完成
异步 1 0.2ms 几乎瞬间完成
异步 0 0.2ms 几乎瞬间完成结论:性能只在于是否将客户端设置成异步写入,acks对性能的影响微乎其微。
但上述的测试是在MAC本地环境进行的,有几项因素不够稳定:
- kafka集群的内存很小
- 磁盘IO和实际情况差别较大
- 集群规模过小
- partition数量很少(集群和partition数量很小能够部分解释为什么acks的改动基本上不影响性能)
因此上述测试的结论主要是参考价值,不能作为最终结论。如果后续需要严谨结论的话,需要在真实机器上测试,并需要开启go的profiling,观察下kafka类库中的写入到底是怎么完成的,以及kafka集群的响应情况。此外,即便是模拟集群1秒左右的同步写入速度也实在是太慢了,后续还需要深入profiling,到底这1秒做了什么(无论是kafka还是go客户端)。
10. TODO
- 深入研究Kafka的监控Metrics
- Kafka集群同步写入性能较低的原因解析
资料
链接
- Apache kafka中文手册
- 分布式队列编程:从模型、实战到优化
- 分布式队列编程优化篇
- 如何保证消息队列的高可用和幂等性以及数据丢失,顺序一致性
- 消息中间件选型分析:从 Kafka 与 RabbitMQ 的对比看全局
- 滴滴出行基于 RocketMQ 构建企业级消息队列服务的实践
- Why is Kafka pull-based instead of push-based?
- Modern Open Source Messaging: NATS, RabbitMQ, Apache Kafka, hmbdc, Synapse, NSQ and Pulsar
- Kafka消费组(consumer group)
- How multiple consumer group consumers work across partition on the same topic in Kafka?
- kafka中partition和消费者对应关系
- Understanding the ‘enable.auto.commit’ Kafka Consumer property
- Monitoring Kafka performance metrics - P1
- Monitoring Kafka performance metrics - P2
- danielqsj/kafka_exporter
- Monitoring Kafka
- Kafka 数据可靠性深度解读
- Building Apache Kafka cluster using docker-compose and VirtualBox
- Deploying a Kafka broker in a Docker container
- Running Kafka in Production
- 比拼Kafka,大数据分析新秀Pulsar到底好在哪
- High performance messaging with Apache Pulsar
- 选择 Pulsar 而不是 Kafka 的 7 大理由
- prometheus/jmx_exporter
- sscaling/jmx-prometheus-exporter
- danielqsj/kafka_exporter
- danielqsj/kafka-exporter
- oded-dd/prometheus-jmx-kafka
- Mousavi310/kafka-grafana
EOF