分布式系统实战
1. 前言
分布式系统因其使用的组件较多,复杂度较高,较难掌握。常说,写出一个能跑的东西很简单,但要全面掌握一门技术,并能够在任何情况下解决其发生的问题,则要难得多得多。分布式系统的难,更多的在于使用的组件多,每一个组件如果都需要掌握其从设计到运行的一系列技术细节就非常困难。此外,分布式系统的监控和分析也很难,也是因其组件多造成的,一个请求流转于多个组件之间,就很难定位当问题发生的时候其源头何在。
在长期的工作中,一直都没有实地进行实践的机会(公司体量、投入、团队管理等各种因素),因此就萌生了自己做一个实践项目,然后在云服务器上部署进行测试实验的念头。在此付诸实行。
1.1 相关资源清单
下面将大量资料进行清单整理,方便后续取用。
1.1.1 实践代码 {#PRACTICE_CODE}
该项目的实际实践代码在:dist-system-practice/golang/src/dist-system-practice/。该处的README主要提供了:
- 应用程序(Web、Service、Consumer)的环境变量清单
- 开发环境的组件清单及端口描述
- 开发环境的部署及启动命令
- 代码文件结构描述
线上环境的部署、启动、测试、导出数据等功能的相关实现在脚本:cluster/src/index.ts。其功能及使用描述在:README.md。
线上服务器拓扑及服务网格相关的配置在:index.ts#L22。
Grafana数据导出相关配置在:index.ts#L151。
1.1.2 组件实验代码
部分组件的简单实验代码在:dist-system-practice/experiment/。
1.1.3 go语言实验代码
go语言的简单实验代码在:dist-system-practice/golang/src/experiment/。
1.1.4 组件专题
对于项目中使用到的一系列组件,我这里都做过比较深入的使用测试及调研,并制作了一系列的专题博文。可以参见列表:2. 组件清单。
2. 组件清单 {#COMPONENT_LIST}
实践项目中(计划)使用到了如下组件:
| 组件 | 角色 | 专题 |
|---|---|---|
| Golang | 应用程序 | Golang Notes |
| MySQL | 数据库 | Draft |
| Memcached | 缓存 | Memcached Notes |
| Docker | 底层容器 | Docker Notes |
| Envoy | 代理入口 | Envoy Notes |
| gRPC | 组件通讯 | gRPC Notes |
| Kafka | 消息队列 | Kafka Notes |
| Prometheus | 监控系统 | Prometheus Notes |
| Grafana | 监控UI | Grafana Notes |
| Jaeger | 链路追踪 | Jaeger Notes |
| Cassandra | 数据库 | Draft |
| Elasticsearch | 聚合分析 | Elasticsearch Notes |
| Kubernetes | 容器管理 | TODO |
| Istio | 服务编排 | TODO |
| Linux | 操作系统 | Draft |
201902之前,Golang、Docker、Kafka、Elasticsearch、Grafana、Prometheus、Jaeger于我的相关积累基本为0,基本上完全没直接接触过(实践),而到了6月底,我已经可以很熟练启动、使用这些组件,更重要的是完全理解它们的设计、架构,以及性能和部分调优手段。
对于”程序”的理解,以及超快的学习速度和学习能力,才是程序员能够在软件行业一直活下去的关键,我一直如此深信。
3. 架构
因为是一个实验性项目,应用程序的逻辑和架构做的非常简单。
3.1 组件列表
- Web:go语言编写的web服务器,整个集群的入口
- Service:go语言编写的gRPC服务器,web收到请求后不进行任何业务实际处理,直接通过gRPC发到Service,由Service处理完成后返回
- Consumer:go语言编写的Kafka消费者,处理部分Service安排到Kafka的异步任务
- Kafka:负责将部分Service的运算进行消息入队,并分发给Consumer处理(异步、解耦)
- MySQL:应用程序的存储服务
- Memcached:应用程序的缓存服务
- Filebeat:负责将Web、Service、Consumer产生的有用日志(过滤)上传到Elasticsearch集群
- Elasticsearch、Kibana:负责将Web、Service、Consumer产生的业务日志索引入库,以便后续查询
- Cassandra:Jaeger Tracing的存储服务
- Jaeger(Agent、Collector、Query):负责接收Web、Service、Consumer发出的Span、Trace数据,入库以便后续查询
- *Exporter:负责将各组件的状态以HTTP的方式输出出来
- Prometheus:将 *Exporter 输出的数据采集,并录入到时序数据库中,以便后续查询
- Grafana:负责将各组件的观察需求固定化,对Prometheus时序数据库进行查询,绘制图表
3.1.1 部分未实践组件
部分列在2. 组件清单中的组件实际上并未实际使用。因时间和精力的原因,只能割舍掉了。
- Envoy:整体业务过于简单,不存在在Web服务器之前架设Envoy的必要性;而内部架构也过于简单,不存在架设Envoy作为内部流量控制入口的必要性
- Kubernetes:实践复杂度过高,因精力原因放弃
- Istio:实践复杂度过高,因精力原因放弃
3.2 数据模型
整个业务流程中只涉及到一个数据模型:
type Work struct {
Id uint32
Viewed uint32
AchievedCount uint32
Achievement string
IsPlanned bool
PlannedAt time.Time
AchievedAt time.Time
Created time.Time
Updated time.Time
}- Id:自增长主键,每一条Work数据唯一
- Viewed:是一个累加的int型,每次
/viewedAPI访问,该值+1 - AchievedCount:是一个累加的int型,每次完成
/planAPI的任务推送及Consumer的achievement更新之后,该值+1 - Achievement:该值由Service的
/planAPI推送任务到Kafka,然后由Consumer获取任务之后进行运算并更新 - IsPlanned:状态标识,当
/planAPI完成之后标记为true,当Consumer运算并更新完成后标记为false - PlannedAt:时间
- AchievedAt:时间
- Created:时间
- Updated:时间
3.3 业务流程
Web服务器
应用程序的入口为go语言编写的web服务器(Web),提供5个API(所有的API都不要求提供WorkId,会在API内部自行随机一个WorkId进行处理,方便后续自动化测试):
/work:获取Work数据,并返回/viewed:获取Work数据,并返回Viewed值/achievement:获取Work数据,并返回Achievement值/plan:获取Work数据,并将任务安排到Kafka队列,更新IsPlanned以及PlannedAt字段的值/api:根据设置好的概率(可配置)抽取上述4个接口中的一个进行执行,实际上的性能测试入口
Consumer消费者
Kafka的消费者为go语言编写的服务器,对消息进行处理:从Kafka中获取任务,根据Id获取Work数据,根据计算因子计算出Achievement字符串值,更新IsPlanned、AchievedAt、Achievement字段的值。
3.4 系统架构
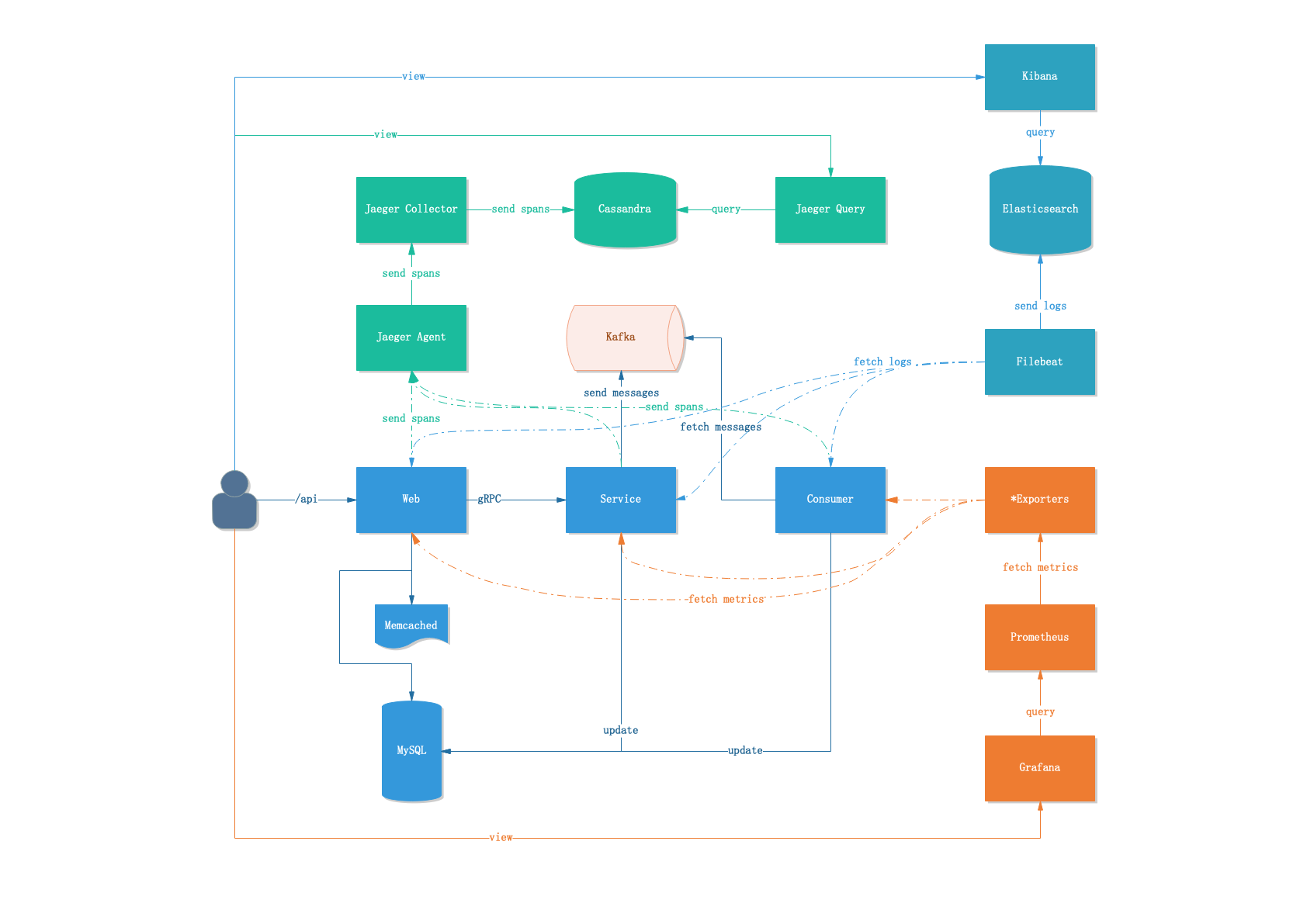
*Exporter这部分比较简略,因为基本上每个组件都有自己的Exporter,要详实还原实际的架构这图就没法看了。因此就只简单列出了go app相关的几条线。
3.5 部署拓扑
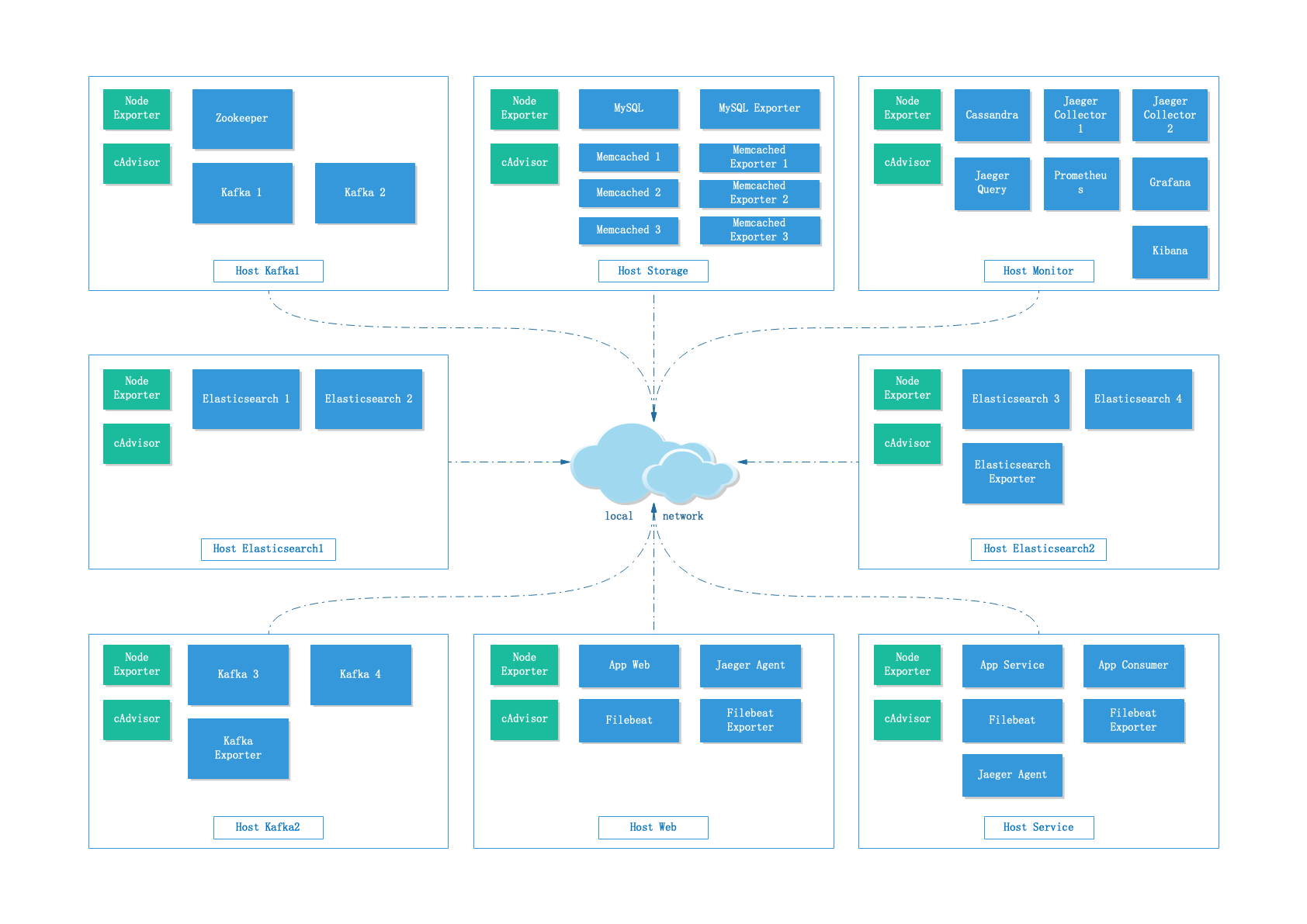
因预算关系,Elasticsearch和Kafka集群的分布并不是特别理想,不过也只能这样了。此外,图中还少了一个Client节点,专门用来运行Vegeta压测客户端的,因比较简单这里就没有绘制上去。
4. 测试
4.1 测试目标 {#TEST_TARGET}
制定测试目标一般需要以下步骤:
- 固定拓扑架构:尽量按线上真实情景的拓扑架构进行测试,如果规模过大的话,可以按比缩小(虽然会失真)
- 设定业务指标:同时在线100万、PV10亿等
- 将业务指标转化为可测试的程序指标:QPS、DB Transaction/s
这样就可以针对可测试的程序指标进行测试了。
而更进一步的测试目标可以细分为两类:
- 测试指标达标:当前系统可以负载起目标需求,在此基础上还可以找出系统的最高负载瓶颈点,并提出优化方案
- 测试指标未达标:当前系统未可以负载起目标需求,需要找出系统的瓶颈,并提出优化方案;后续需要多轮测试以验证优化的执行情况
就当前的项目来说,因为是纯粹的模拟测试项目,所以不存在真实的业务需求和业务指标,因此无法设定具体的程序指标,也就无从谈起是否达标的问题。只能说通过测试慢慢摸索当前架构的性能峰值,以及瓶颈点:
在固定硬件规格、程序拓扑架构之后,逐步提升客户端的QPS,查看系统负载的上升情况,找出系统最高负载值,并找出系统整体的瓶颈点
4.2 测试硬件
这次的测试选用的是Linode的云服务器,在选择的时候首先考虑的当然是国内的服务商,但发现像我这样只需要短期使用资源的客户(几个小时到1天左右)国内的服务商的付费方式太糟糕了。一般来说国内的服务商都是按月付费,所谓的按时收费其单价换算下来要比按月付费高得多得多,因此实际上是不可用的。
海外服务商一开始考虑使用Vultr,毕竟性价比是最高的,但后来发现Vultr对客户有非常严格的限制,如果需要租用大量机器或高性能机器的话,需要发Ticket进行人工审核。不出意外,我这样短期租用的客户被拒了。最后只能选用Linode,Linode在这方面倒是没有额外的限制,随开随用。
实际使用的是Linode的16G机型:6 CPU、16G RAM、320G Storage。简单Benchmark结果如下:
$ wget -qO- bench.sh | bash
----------------------------------------------------------------------
CPU model : AMD EPYC 7601 32-Core Processor
Number of cores : 6
CPU frequency : 2199.996 MHz
Total size of Disk : 315.0 GB (2.2 GB Used)
Total amount of Mem : 16040 MB (120 MB Used)
Total amount of Swap : 511 MB (0 MB Used)
System uptime : 0 days, 0 hour 2 min
Load average : 0.29, 0.22, 0.09
OS : Ubuntu 18.04.2 LTS
Arch : x86_64 (64 Bit)
Kernel : 4.15.0-50-generic
----------------------------------------------------------------------
I/O speed(1st run) : 892 MB/s
I/O speed(2nd run) : 1.1 GB/s
I/O speed(3rd run) : 1.0 GB/s
Average I/O speed : 1014.1 MB/s
----------------------------------------------------------------------
Node Name IPv4 address Download Speed
CacheFly 205.234.175.175 144MB/s
Linode, Tokyo, JP 106.187.96.148 20.7MB/s
Linode, Singapore, SG 139.162.23.4 6.48MB/s
Linode, London, UK 176.58.107.39 9.71MB/s
Linode, Frankfurt, DE 139.162.130.8 15.4MB/s
Linode, Fremont, CA 50.116.14.9 205MB/s
Softlayer, Dallas, TX 173.192.68.18 44.9MB/s
Softlayer, Seattle, WA 67.228.112.250 44.8MB/s
Softlayer, Frankfurt, DE 159.122.69.4 4.92MB/s
Softlayer, Singapore, SG 119.81.28.170 8.21MB/s
Softlayer, HongKong, CN 119.81.130.170 10.4MB/s
----------------------------------------------------------------------
Node Name IPv6 address Download Speed
Linode, Atlanta, GA 2600:3c02::4b 39.3MB/s
Linode, Dallas, TX 2600:3c00::4b 28.9MB/s
Linode, Newark, NJ 2600:3c03::4b 18.3MB/s
Linode, Singapore, SG 2400:8901::4b 5.36MB/s
Linode, Tokyo, JP 2400:8900::4b 20.5MB/s
Softlayer, San Jose, CA 2607:f0d0:2601:2a::4 95.4MB/s
...
----------------------------------------------------------------------$ (curl -s wget.racing/nench.sh | bash) 2>&1 | tee nench.log
-------------------------------------------------
nench.sh v2019.06.29 -- https://git.io/nench.sh
benchmark timestamp: 2019-07-12 05:48:17 UTC
-------------------------------------------------
Processor: AMD EPYC 7601 32-Core Processor
CPU cores: 6
Frequency: 2199.996 MHz
RAM: 15G
Swap: 511M
Kernel: Linux 4.15.0-50-generic x86_64
Disks:
sda 319.5G HDD
sdb 512M HDD
CPU: SHA256-hashing 500 MB
2.962 seconds
CPU: bzip2-compressing 500 MB
6.310 seconds
CPU: AES-encrypting 500 MB
1.362 seconds
ioping: seek rate
min/avg/max/mdev = 62.2 us / 112.5 us / 2.94 ms / 75.5 us
ioping: sequential read speed
generated 16.5 k requests in 5.00 s, 4.03 GiB, 3.30 k iops, 824.3 MiB/s
dd: sequential write speed
1st run: 855.45 MiB/s
2nd run: 1049.04 MiB/s
3rd run: 1049.04 MiB/s
average: 984.51 MiB/s
IPv4 speedtests
your IPv4: 173.255.252.xxxx
Cachefly CDN: 175.13 MiB/s
Leaseweb (NL): 13.85 MiB/s
Softlayer DAL (US): 38.74 MiB/s
Online.net (FR): 11.06 MiB/s
OVH BHS (CA): 16.75 MiB/s
IPv6 speedtests
your IPv6: 2600:3c01::xxxx
Leaseweb (NL): 7.77 MiB/s
Softlayer DAL (US): 0.00 MiB/s
Online.net (FR): 8.44 MiB/s
OVH BHS (CA): 17.60 MiB/s
-------------------------------------------------我是很想把CPU上到至少8个核,但囿于预算,还是降了一档。
4.3 测试规划
上面在4.1 测试目标的时候提到了设定目标需要固定程序拓扑架构,但即便在程序架构固定的情况下,仍旧有大量细节(参数、配置)是可以微调变动的:
- 客户端连接数量:最大连接数,越大的最大连接数意味着越高的并发请求可能,而提升并发意味着负载的显著上升
- 客户端请求速率:同时到达服务器的请求数量,即并发请求数量,并发数量的上升最终体现在这个指标的提升上
- 数据库表量级:不同数据量的数据库表,其性能也会显著不同,因此在测试的时候也可以变动下表数据量再进行测试
- 数据库连接:少量的连接不足以处理请求,但过大的连接数也会显著降低性能,这方面也是一个测试点
- gRPC连接池容量:虽然gRPC的Go客户端对于并发的处理非常好,但连接池仍旧在某些情况下有其作用,如何找出合理的并发池容量也是可选的测试条目之一
- Kafka目标Topic的分片数量:提升分片数量会降低写入的性能,但更多的分片意味着更多的消费者,消息的处理速度会上升
- Elasticsearch集群的Node数量:提升节点会降低写入性能,但会提升查询性能
- JVM设置:各个用到JVM的软件一般都需要很精细地对JVM进行配置和调优,才能很好地发挥性能,而这方面的配置变化对测试的影响也很大
- 消费者计算因子:随着因子数值的调大,计算量会显著上升,最终会体现在Consumer角色的负载上升,以及Kafka队列的堆积不能及时消费等
测试的规划制定需要固定大部分的变量、配置,仅修改少部分,然后进行多次测试,横向比较性能的变化,就可以找出当前架构的最佳性能表现设置。
4.4 监控清单
下面是一份当前程序架构中需要进行重点监控的程序指标清单。这部分太长了,我放到最后的Appendix > 监控清单里,以便不影响下文的阅读。
4.5 部署工程
部署工作:
- 在Linode服务商这里申请开服务器
- 因Linode不支持在开服务器的时候直接部署SSH Key,需要使用命令来部署:ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
- 使用1.1.1 实践代码提到的线上部署脚本进行部署:
- ./cluster.sh —machine
- ./cluster.sh —image
- ./cluster.sh —deploy —machine-type=all
- 使用 ./cluster.sh —docker-ps —machine-type=all 来观察是否启动正常
- 打开 MONITER_IP:9090 来查看是否所有的监控节点都正常在线
- 打开 MONITER_IP:5601 来设置ES内的Index Pattern
- 使用 curl -v http://WEB_IP:8000/work 等入口测试是否正常运行
4.6 测试执行 & 报告制作
部署完成之后:
- 记录测试开始时间
- 修改cluster.sh内相关配置
- 运行 ./cluster.sh —stress —machine-type=all 获得测试命令
- 在Client Host上执行测试命令开始测试,并观察实时报表中的报错数及响应时长变化(如有大量错误和大量超时,需要中断测试,并查找原因)
- 打开 MONITER_IP:9090 观察监控节点是否正常在线
- 打开 MONITER_IP:3000 观察监控指标变化
- 在测试完成前,使用pprof获取30秒间隔的两份堆内存dump(Web、Service、Consumer都需要):
- go tool pprof http://HOST:PORT/debug/pprof/heap
- Saved profile in /Users/XXX/pprof/pprof.web.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz
- go tool pprof -png /Users/XXX/pprof/pprof.web.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz > web_heap.png
- go tool pprof http://HOST:PORT/debug/pprof/heap
- 在测试完成之前,使用pprof获取30秒的CPU dump(Web、Service、Consumer都需要):
- go tool pprof http://HOST:PORT/debug/pprof/profile?seconds=30
- Saved profile in /Users/XXX/pprof/pprof.web.samples.cpu.001.pb.gz
- go tool pprof -png /Users/XXX/pprof/pprof.web.samples.cpu.001.pb.gz > web_cpu.png
- go tool pprof http://HOST:PORT/debug/pprof/profile?seconds=30
测试完成后:
- 记录测试结束时间
- 修改cluster.sh内相关配置
- 使用 ./cluster.sh —report 导出测试结果数据
- 手动获取Elasticsearch数据,并填入到报表模板中
- 获取时间段内所有Web请求数量,与客户端报表中数值进行比对是否匹配
- 获取时间段内所有的Consumer请求数量,与Web请求中的 /plan 数量进行比对是否匹配
- 获取时间段内所有Web请求API类型的配比,与配置项中的数值进行比对是否匹配
- 手动获取Jaeger数据,并填入到报表模板中
- 时间段内各Web API的耗时图表
- 将压测执行客户端的报表数据填入到报表模板中
- 将之前导出的CPU和堆内存Profiling数据以图片形式导出,并填入到报表模板中
- 修改导出的报表模板,添加测试实际配置数据,并编写结论板块内容
- 将完工的所有内容提交到代码库中:
- cluster/report/XXXXX/images
- cluster/report/XXXXX/report_XXXXX.md
- cluster/report/XXXXX/pprof/* 导出的CPU和堆内存dump
- cluster/output/*
4.6.1 获取Elasticsearch(Kibana)数据
- 获取所有Web请求数:
- 打开Discover > dist-web-web-7.0.0-*
- 调整时间成绝对时间
- 查看左上角的Hit数:1,552 hits
- 获取所有Consumer请求数:
- 打开Discover > dist-consumer-consumer-7.0.0-*
- 调整时间成绝对时间
- 查看左上角的Hit数:81 hits
- 比率验证:81 / 1552 = 5.21%;OK
- 获取API GetWork请求数:
- 打开Discover > dist-web-web-7.0.0-*
- 调整时间成绝对时间
- 在Filter中输入:
api: apiGetWork - 查看左上角的Hit数:704 hits
- 比率验证:704 / 1552 = 45.36%;OK
- 获取API UpdateViewed请求数:
- 打开Discover > dist-web-web-7.0.0-*
- 调整时间成绝对时间
- 在Filter中输入:
api: apiUpdateViewed - 查看左上角的Hit数:364 hits
- 比率验证:364 / 1552 = 23.45%;OK
- 获取API GetAchievement请求数:
- 打开Discover > dist-web-web-7.0.0-*
- 调整时间成绝对时间
- 在Filter中输入:
api: apiGetAchievement - 查看左上角的Hit数:403 hits
- 比率验证:403 / 1552 = 25.96%;OK
- 获取API PlanWork请求数:
- 打开Discover > dist-web-web-7.0.0-*
- 调整时间成绝对时间
- 在Filter中输入:
api: apiPlanWork - 查看左上角的Hit数:81 hits
- 数量验证:与Consumer计数匹配;OK
P.S 使用level: error过滤条件查找错误日志,如果是没有上传日志的service服务等,则需要:
- docker-machine ssh service
- docker logs —tail 1000 app_service | grep ERROR
4.6.2 获取Jaeger数据
- 打开Jaeger Query
- 将Lookback设置为:Custom Time Range
- 设置Start Time和End Time
- 设置Service为:app.web
- 设置Operation为:
- Web.HandleApi.apiGetWork
- Web.HandleApi.apiUpdateViewed
- Web.HandleApi.apiGetAchievement
- Web.HandleApi.apiPlanWork
- 设置Limit Results为最大值1500
- 查看右上角的耗时分布图以及查询数
- 选择几个耗时比较大的个例,点击观察原因
5. 报告
经过实机测试,报告如下,有兴趣的可以打开看看:
5.1 第一次测试
1000qps测试发现瓶颈点(预设瓶颈,意料之中)Consumer CPU消耗过于剧烈。
5.2 第二次测试
解决Consumer的瓶颈问题,并对其进行验证。
因预算和时间等原因,后续并没有展开更多的测试,仅两次,一次演示问题的发现,一次演示问题的解决和验证。
Appendix
监控清单 {#MONITORING_LIST}
Host
Dashboard uid: 9CWBz0bik
Graph params:
- var-interval=5s 调整图表的采样间隔,最低5s
- var-env=All 固定值
- var-name=All 固定值
- var-node=192.168.3.111%3A9100 label_values(node_exporter_build_info,instance)
- var-maxmount= 固定值
- panelId=13 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- 系统运行时间
- panelId=15
- CPU 核数
- panelId=14
- 内存总量
- panelId=75
- CPU使用率(5m)
- panelId=167
- CPU iowait(5m)
- panelId=20
- 内存使用率
- panelId=172
- 当前打开的文件描述符
- panelId=16
- 根分区使用率
- panelId=166
- 系统平均负载
- panelId=13
- 磁盘总空间
- panelId=171
- 各分区可用空间
- panelId=164
- CPU使用率、磁盘每秒的I/O操作耗费时间(%)
- panelId=7
- 内存信息
- panelId=156
- 磁盘读写速率(IOPS)
- panelId=161
- 磁盘读写容量大小
- panelId=168
- 磁盘IO读写时间
- panelId=160
- 网络流量
- panelId=157
- TCP 连接情况
- panelId=158
Container
Dashboard uid: PV1XyHnWz
Graph params:
- refresh=30s 不生效,但建议保留
- var-containergroup=All 固定值
- var-interval=30s 调整图表的采样间隔,最低30s
- var-server=192.168.3.111 label_values(node_boot_time_seconds, instance) /([^:]+):.*/ 去掉了instance的port
- var-name=prometheus 容器名
- panelId=8 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Received Network Traffic per Container
- 容器收到的网络流量
- panelId=8
- Sent Network Traffic per Container
- 容器发送的网络流量
- panelId=9
- CPU Usage per Container
- 容器消耗的CPU
- panelId=1
- Memory Usage per Container
- 容器消耗的内存
- panelId=10
- Memory Swap per Container
- 容器的交换内存
- panelId=34
Memcached
Dashboard uid: NgzwcO7Zz
Graph params:
- var-node=memcached-exporter%3A9150 label_values(memcached_up, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- % Hit ratio
- 命中率
- panelId=1
- Connections
- 连接数
- panelId=4
- Get / Set ratio
- Get Set比率
- panelId=3
- Commands
- 按种类显示命令执行的数量
- panelId=2
- evicts / reclaims
- Key驱逐数量
- panelId=8
- Read / written bytes
- 网络流量
- panelId=6
- Total memory usage
- 内存使用率
- panelId=7
- Items in cache
- 内存中Key数量
- panelId=5
MySQL
Dashboard uid: MQWgroiiz
Graph params:
- var-interval=1m 调整图表的采样间隔,最低1s
- var-host=mysqld-exporter%3A9104 label_values(mysql_up, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- MySQL Connections
- 连接状态
- panelId=92
- MySQL Aborted Connections
- 退出的连接统计
- panelId=47
- MySQL Client Thread Activity
- 线程活动状态
- panelId=10
- MySQL Thread Cache
- 线程池状态
- panelId=11
- MySQL Questions
- 查询数量
- panelId=53
- MySQL Slow Queries
- 慢查询数量
- panelId=48
- MySQL Table Locks
- 表锁状态
- panelId=32
- MySQL Network Traffic
- 网络流量统计
- panelId=9
- MySQL Network Usage Hourly
- 网络流量统计/小时
- panelId=381
- MySQL Internal Memory Overview
- 内部内存使用状态
- panelId=50
- Top Command Counters
- 执行命令按种类分类数量
- panelId=14
- Top Command Counters Hourly
- 命令数量/小时
- panelId=39
- MySQL Query Cache Memory
- 缓存使用量
- panelId=46
- MySQL Query Cache Activity
- 缓存命中状态
- panelId=45
- MySQL File Openings
- 实时打开的文件数量
- panelId=43
- MySQL Open Files
- 打开文件统计
- panelId=41
Prometheus
Dashboard uid: 54e7hO7Wk
Graph params:
- var-job=prometheus 固定值
- var-instance=prometheus 固定值
- var-interval=1h 调整图表的采样间隔,最低1h
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Series Count
- 时序数量
- panelId=3
- Failures and Errors
- 采样出错
- panelId=33
- Appended Samples per Second
- 每秒采样数量
- panelId=4
- Scrape Duration
- 采样耗时
- panelId=29
- 该图表按instance进行显示,因此如果需要查询某个特定服务的采样抓取耗时,需要调整该参数,不能固定使用prometheus
- Prometheus Engine Query Duration Seconds
- 查询耗时情况
- panelId=15
Kafka JMX
Dashboard uid: chanjarster-jvm-dashboard
Graph params:
- var-datasource=Prometheus 固定值
- var-job=kafka 固定值
- var-instance=kafka_1%3A7071 label_values(jvm_info{job=“$job”},instance)
- var-mempool=All 固定值
- var-memarea=All 固定值
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Open file descriptors
- 文件打开情况
- panelId=38
- CPU load
- CPU使用情况,含JVM的统计区分
- panelId=29
- Memory area [heap]
- 堆内存使用情况
- panelId=8
- Memory area [nonheap]
- 堆外内存使用情况
- panelId=45
- GC count increase
- GC数量
- panelId=6
- GC time
- GC耗时
- panelId=5
- Threads used
- 线程数量
- panelId=3
- Physical memory
- 物理内存情况
- panelId=44
Kafka Exporter
Dashboard uid: jwPKIsniz
Graph params:
- var-job=kafka-exporter 固定值
- var-instance=kafka_exporter%3A9308 label_values(kafka_consumergroup_current_offset{job=~“$job”}, instance)
- var-topic=All 固定值,可调整
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Message in per second
- 每秒消息数量
- panelId=14
- Lag by Consumer Group
- 消费组延迟
- panelId=12
- Message in per minute
- 每分钟消息数量
- panelId=16
- Message consume per minute
- 每分钟消息消费
- panelId=18
Jaeger Agent
Dashboard uid: Z8ieXpnWk
Graph params:
- var-node=jagent_web%3A5778 label_values(jaeger_agent_thrift_udp_server_queue_size, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Reporter batches submitted
- Reporter批量提交数(提交至collector)
- panelId=6
- Reporter batches failures
- Reporter批量提交失败数
- panelId=8
- Reporter spans submitted
- Reporter span提交数量
- panelId=10
- Reporter spans failures
- Reporter span提交失败数
- panelId=12
- Queue size
- Receiver等待队列(从app过来)
- panelId=24
- Read errors
- ReceiverUDP读取错误数
- panelId=26
- Packets processed
- Receiver处理的包数量
- panelId=20
- Packets dropped
- Receiver丢弃的包数量
- panelId=22
Jaeger Collector
Dashboard uid: mb6-JR5iz
Graph params:
- var-node=jcollector_1%3A14268 label_values(jaeger_collector_queue_length, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Traces received
- 收到的trace数量
- panelId=20
- Traces rejected
- 拒绝的trace数量
- panelId=22
- Spans received
- 收到的span数量
- panelId=18
- Spans dropped
- 丢弃的span数量
- panelId=4
- Spans rejected
- 拒绝的span数量
- panelId=24
- Queue length
- 队列长度
- panelId=2
- Span queue latency - 95 percentile
- span处理时长 95%
- panelId=10
- Save latency - 95 percentile
- 数据库存储时长 95%
- panelId=26
- Cassandra attempts
- cassandra数据库请求数量
- panelId=16
- Cassandra errors
- cassandra数据库报错
- panelId=12
Filebeat
Dashboard uid: oF_Qr14Zz
Graph params:
- var-node=filebeat_exporter%3A9479 label_values(filebeat_uptime_seconds, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Harvester
- 追踪文件的状态
- panelId=2
- IO errors
- IO错误
- panelId=8
- Filebeat events
- filebeat事件
- panelId=4
- Output events
- 输出事件
- panelId=6
- Pipeline events
- 管线事件
- panelId=10
- Pipeline queue
- 管线队列
- panelId=12
Elasticsearch
Dashboard uid: FNysokSWk
Graph params:
- var-interval=5m 调整图表的采样间隔,最低5m
- var-cluster=es_cluster 固定值
- var-name=es_1 label_values(elasticsearch_indices_docs{cluster=“$cluster”, name!=""},name)
- var-instance=es_exporter%3A9114 固定值
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Pending tasks
- 集群未完成工作数
- panelId=16
- Load average
- 节点负载
- panelId=30
- CPU usage
- 节点CPU使用
- panelId=88
- JVM memory usage
- 节点内存使用
- panelId=31
- GC count
- GC次数
- panelId=7
- GC time
- GC耗时
- panelId=27
- Total translog operations
- 持久化操作数
- panelId=77
- Total translog size in bytes
- 持久化容量
- panelId=78
- Tripped for breakers
- 断路器触发次数
- panelId=79
- Estimated size in bytes of breaker
- 断路器触发限制
- panelId=80
- Disk usage
- 磁盘用量
- panelId=32
- Network usage
- 网络用量
- panelId=47
- Documents count on node
- 文档数量
- panelId=1
- Documents indexed rate
- 文档索引数
- panelId=24
- Documents merged rate
- 文档合并率
- panelId=26
- Documents merged bytes
- 文档合并量
- panelId=52
- Query time
- 查询耗时
- panelId=33
- Indexing time
- 索引耗时
- panelId=5
- Merging time
- 合并耗时
- panelId=3
- Total Operations rate
- 所有操作速率
- panelId=48
- Total Operations time
- 所有操作耗时
- panelId=49
Golang
Dashboard uid: ypFZFgvmz
Graph params:
- var-job=go-apps 固定值
- var-interval=1m 调整图表的采样间隔,最低1m
- var-node=192.168.3.111%3A8000 label_values(go_memstats_alloc_bytes, instance)
- panelId=1 根据图表,编号各自不同
- width=1000&height=500 图表大小
- tz=Asia%2FShanghai 用户时区
Sample graph link: link
Monitoring items:
- Heap memory
- 堆内存用量
- panelId=1
- Heap memory trends
- 堆内存申请和释放情况
- panelId=4
- Heap objects
- 堆内存对象数量
- panelId=2
- Heap system alloc
- 堆内存向系统申请和释放情况
- panelId=5
- GC rate
- GC频次
- panelId=3
- Next gc target
- 下次GC触发容量
- panelId=6
- GC duration quantiles
- GC耗时情况,分25% 50% 90%三段
- panelId=8
- Goroutines count
- goroutine数量
- panelId=7
- Threads count
- 线程数量
- panelId=10
EOF