Elasticsearch Notes
1. 前言
之前做了Prometheus和Jaeger相关的调研工作,这两者虽然也涉及到日志聚合相关的技术或是类似的技术,但毕竟不是通用的日志聚合系统。通用的日志聚合系统需要能接受任何类型的日志,并将其索引入库以备后续的查询。市面上这方面的产品现在基本上是Elasticsearch为主要选择,已经可以说是很成熟了。所以这块需求我这里也是以ELK为第一备选进行相关的调研。
后续的调研内容版本如下:
elasticsearch 7.0.0
elastic/filebeat 7.0.0
kibana 7.0.0在提到Elasticsearch的时候我们一般不会只说Elasticsearch本身,而是会提到ELK这个词,这里说的其实就是从日志采集、清洗、转换、分发、到最后入库的整个流程,以及查询用的面板包含在内的一整套生态。因此下面行文会从:日志采集、日志存储、日志查询三方面着手。
官方文档:
- Elastic Stack and Product Documentation
- Elasticsearch Reference
- Filebeat Reference
- Kibana User Guide
2. Log Shipper
日志是在各个应用程序中生产的,此外也包括了操作系统级别的日志生产。因此日志的产生这个行为是分散在各个节点上的,日志的收集就是从分散的节点采集数据汇集到中心存储的一个过程,这也是所谓的聚合。而从分散的节点上采集数据,我们需要Agent(Log Shipper)来执行这个操作。
经典的ELK中,L代表的就是日志采集Agent:Logstash。当然,市面上也有非常多的其他选择,可以做到和Logstash类似的功能。从系统设计上来说,ELK三者本身是完全解耦分离的,所以所谓的ELK堆栈,只是一种经过验证的实践方案,其实中间除了E之外,L和K都是可以自由更换的。
2.1 横向比较 & 选择
关于日志采集组件的备选有大量横向比较,推荐阅读:5 Logstash Alternatives。这篇的时间还算比较新2018-10-09,讲解也非常到位,基本上看这篇就OK了。
此外,StevenACoffman/fluent-filebeat-comparison.md也可以看下。
排除比较年轻的项目,以及资历不太雄厚的项目,剩下的主要选项有三个:
- Logstash
- 优势:功能强大;经过实践检验
- 劣势:资源占用过大;JVM
- Filebeat
- 优势:Go语言;部署简单;资源占用极小
- 劣势:功能相对简单
- Fluentd
- 优势:CNCF孵化项目
- 劣势:Ruby语言实现
Log Shipper作为每个应用程序都需要附加的边车组件其中之一,Logstash的内存和CPU消耗在某些情况下是完全不能接受的(1GB内存,开玩笑)。JVM众所周知是比较难搞的虚拟机,如果要用好,调优需要有非常专门的知识,所以算是一个减分项。但放在Elasticsearch堆栈上来说,倒也不是那么严重,因为你无论如何都需要JVM知识来调优Elasticsearch本身。功能强大是Logstash的最大优势,能满足基本上所有的应用场景,在某些架构上,即便使用了Filebeat等高效轻量级的Log Shipper,在进入Elasticsearch入库之前仍旧需要一个Logstash来进行转换等工作。
Filebeat基本上没有缺点,如果它的功能能满足你的需求的话。如果不能满足,那么最新的Kafka输出能解决你的问题。使用Filebeat作为边车的Log Shipper,输出到Kafka,然后使用Logstash或者自己编写的组件来消费Kafka里的日志,最终入库到Elasticsearch。
Fluentd的最大优势在于CNCF的加持(背书)。但基于我多年的编程经验,ruby的性能一般来说是不可靠的,甚至使用JVM的Logstash都已经为性能付出了过大的代价,我又有什么理由要去相信口碑一直不怎么样的ruby呢。Logstash至少使用的JVM还和Elasticsearch本身是一个技术栈的,Fluentd会引入一个完全新的ruby虚拟机,就更加增加系统复杂度了。甚至,我在调研的初期就随手找到了:Fluentd retains excessive amounts of memory after handling traffic peaks #1657,2017年的BUG,到现在还是Open状态。
综上所述,任何情况下都应该使用Filebeat作为边车的Log Shipper。Filebeat能满足需求的直接入库到Elasticsearch,不能满足需求的日志进Kafka,然后使用Logstash或其他Consumer来进行转换,最终入库到Elasticsearch。
2.2 架构设计
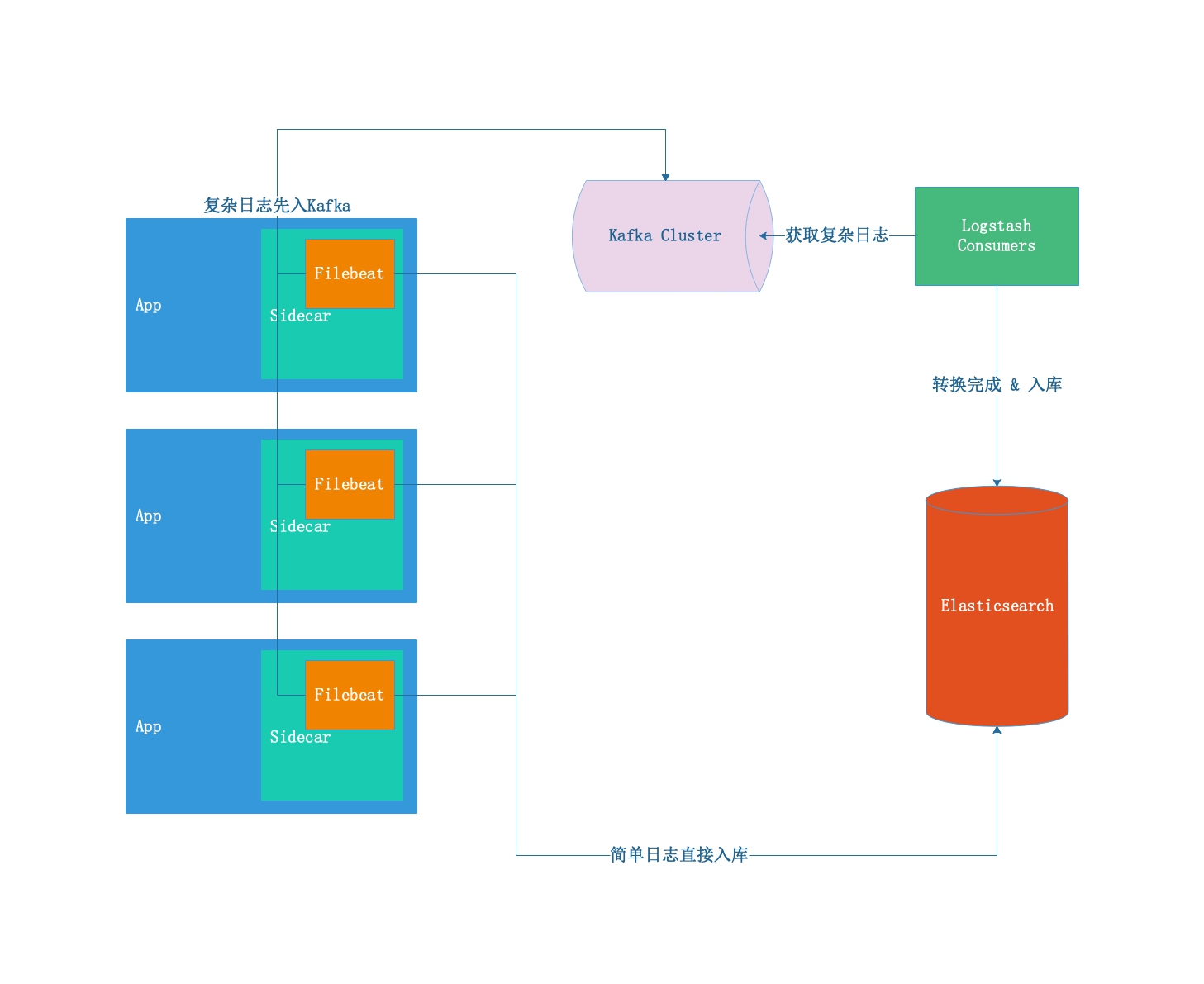
图中的Logstash部分可以替换成自编写的轻量级Consumer。
3. Filebeat
非常细节的使用及配置,可以查看这篇中文的博客:Filebeat 模块与配置。
3.1 设计 & 基础概念
这张图看看就好,意义不大。
Filebeat是一种Elastic Beat,其实现基于libbeat框架,更多的可以查看:Beats Platform Reference。
工作流:
- 输入:从指定的文件进行监控日志增加行为,并触发读取发送
- 输出:可直接向Elasticsearch集群发送日志,也可以将日志输出到外部的消息队列(Kafka)里
- 模块:对某些日志进行的采集行为及Elasticsearch集群对这些日志进行分析的配置化和固化
- 消费:Elasticsearch集群解析日志入库,或从Kafka读取日志然后解析入库
3.2 使用
部分说明文档:
- 安装请参照:Step 1: Install Filebeat
- 配置请参照:Step 2: Configure Filebeat
- 容器内运行:Running Filebeat on Docker
3.3 模块
官方文档:Modules overview。
Elasticsearch Ingest Node pipeline definition, which is used to parse the log lines.
首先明确一点,Filebeat的模块并不是一般意义上的功能模块。按软件设计思维来说,模块意味着功能的拓展,意味着根据模块设计的要求(框架)可以将软件本身能做的事情大幅拓展。而Filebeat的模块则不是,在Filebeat里,模块意味着一系列既有行为的组合:
- Nginx有两个日志:access和error
- Nginx在Elasticsearch上处理的Ingest Pipeline是XXX
- Nginx的日志格式是XXX,Elasticsearch里对应的字段是XXX
- Nginx日志对应的Kibana面板有XXX,可以看到XXX数据
从上面的例子可见:Filebeat本身并没有做什么,它做的仍旧只是采集日志,发送出去,没了。只不过指定了Elasticsearch集群中处理这个日志的Ingest Pipeline是谁,日志应该怎么入库(事情是在Elasticsearch集群上完成的)。因此在功能性上Filebeat是不可能替代Logstash的,它的定位只是轻量级的应用端Log Shipper,如果要在功能上覆盖Logstash的功能点,就需要使用Elasticsearch自身的Ingest Pipeline,仍旧需要Filebeat以外的系统支持。
部分文档:
- 如何创建一个新的模块:Creating a New Filebeat Module
- 模块清单:Modules
- 命令行列出模块:
$ docker run --rm \
--name filebeat \
elastic/filebeat:7.0.0 modules list3.4 过滤和丰富
Filebeat可以在配置中指定一些受限的过滤和清洗功能:Filter and enhance the exported data。
可选的processor清单有:Define processors。
触发的条件:Conditions。
3.5 文件状态记录 & 投递保证
Filebeat对于输入的日志文件,会制作一个本地的注册文件,将状态都保存下来,因此在重启或者挂掉重新拉起来之后,Filebeat总是能知道之前发送到哪里。
Filebeat会保证本地的日志文件至少被输出一次,如果在输出的结果返回之前Filebeat就挂掉的话,在下次Filebeat启动之后,它还会将之前最后的日志再投递一次(对于Filebeat来说,它并不知道自己死前已经投递过一次,并被输出方接收到了)。因此,收取数据的服务端可能在某些情况下收到重复的数据。
4. Elasticsearch
2套电子书非常不错:
对于作为Elasticsearch底层的Lucene有兴趣的,可以查看这篇:Lucene 查询原理及解析。
4.1 知识点
这一节基本上都是简单的知识点和概念罗列,主要阐明:“这是什么”。详细的内容会在后续的章节里分析。
4.1.1 基础概念
官方文档:Basic Concepts。
提到了几点:
- Near Realtime (NRT)
- Cluster
- Node
- Index
- Document
- Shards & Replicas
4.1.2 安装 & 配置
- Install Elasticsearch with Docker
- Configuring Elasticsearch
- Setting JVM options
- Important Elasticsearch configuration
- Important System Configuration
后面三条对生产环境影响比较大,需要仔细阅读。更贴近实践的范例可以参见:8.1 Elasticsearch配置。
4.1.3 API
Elasticsearch的API文档相当散,主要是以下几项:
API最常见的用途是对Elasticsearch集群进行观察,并进行一些例如Index Template设置之类的,超乎于日常日志输入相关业务之外的管理和控制。
4.1.4 Query DSL
官方文档:Query DSL。
了解Elasticsearch的人肯定会问:Query DSL和Elasticsearch的基础Lucene之间是什么关系。关于这个知识点可以查看:What is the difference between Lucene and Elasticsearch。
Elasticsearch is a JSON Based, Distributed, web server build over Lucene. Though it’s Lucene who is doing the actual work beneath, Elasticsearch provides us a convenient layer over Lucene. Each shard that gets created in Elasticsearch is a separate Lucene instance.
Lucene是底层,Elasticsearch是基于Lucene之上的超集开发,而QueryDSL则是用户和Elasticsearch之间交互的桥梁。
4.1.5 SQL
Elasticsearch还可以使用SQL进行查询:SQL access。
4.1.6 Ingest节点
在整个Elasticsearch集群中,有一部分节点是用来进行日志过滤、清洗、丰富化的,这些工作在这个设计出现之前是只能在Agent上实现的,一般来说就是Logstash,而现在在服务器节点上也可以处理相对应的工作了。
官方文档:Ingest Node。
通过定义Processors来进行日志的解析和处理:Processors。
初步了解下来功能应该还算强大,可以使用脚本化代码进行功能拓展:
此外还有插件机制:Ingest Plugins。
4.2 文档数据库 & 索引 {#ID_INDEX}
Elasticsearch是一个文档数据库,从本质上来看,它和Mongo其实相当类似。和传统RDBMS比较起来:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Cluster -> Indices -> Documents -> Fields简单理解:所谓的索引就是表名,用来定位查询以及根据该名字进行分片sharding。
举个例子: PUT /employee/1
Index:employee
Document:
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}Fields:
- first_name
- last_name
- age
- about
- interests
索引非常重要,在集群模式(cluster)中,索引是用来进行分区的唯一指标。Elasticsearch会根据Index来决定当前数据落到哪台实际的存储服务器上。
此外,需要注意,Index可以被Reindex,但不可以Reshard。换句话说,在Index被创建出来的时候,其shards数量就已经被固定下来了,以后不可更改。如果有这样的需求的话,必须使用Reindex来重新分配并平衡Index,已经创建出来的就没办法了。而Replicas则可以随时更改数量。
关于索引的细节,以及一些集群相关的索引知识,可以查看:Index API。
4.2.1 Index Template
和索引(Index)息息相关的有一个概念叫:Index Template。这部分比较重要也稍微有点复杂,后面会结合实际实践一并解释,会更容易理解:6.3 Index Template。
4.2.2 设置index生命周期
一般实践的时候,建议不要向单个Index内放入过多的文档,这会对写入和查询都造成比较大的压力。比较常见的做法是对输出端进行设置,将日志的输出索引设置成按日划分:index: "dist-%{[fields.app]}-%{[fields.module]}-%{[agent.version]}-%{+yyyy.MM.dd}",这样就有一个最基本的保障。但这样做的缺陷一样非常明显,当单日的业务量上涨之后,单日的日志量可能就比较夸张。
在Elasticsearch中,Index的生命周期有另外的管理方法:Getting started with index lifecycle management。
同时需要在Filebeat端进行配合:Configure index lifecycle management。
4.2.3 Index的自动创建设置
在大部分情况下Elasticsearch都是允许自动创建Index的。在某些情况下可能需要关闭自动创建的允许权限,可以参见文档:Automatic Index Creation,来查看如何操作。
4.3 存储 {#ID_STORAGE}
在官方手册文档中,并没有关于存储相关的设计及实现的详细内容。在Blog中找到一篇:A Dive into the Elasticsearch Storage,不过时间也稍微有点久,但还算可以用来一窥存储相关的技术点。
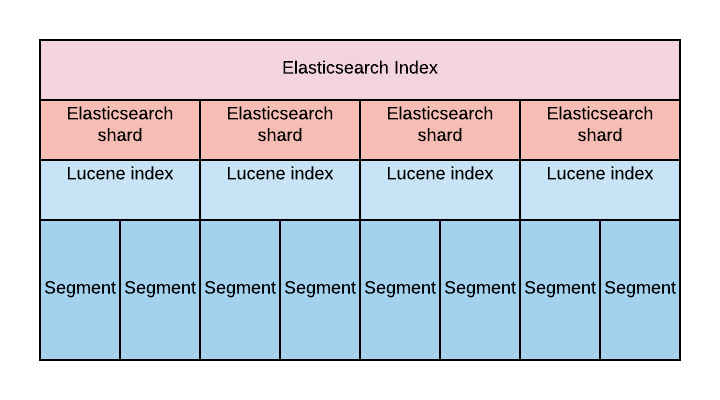
此外,shards:Lucene segments
Each Elasticsearch index is divided into shards. Shards are both logical and physical division of an index. Each Elasticsearch shard is a Lucene index. The maximum number of documents you can have in a Lucene index is 2,147,483,519. The Lucene index is divided into smaller files called segments. A segment is a small Lucene index. Lucene searches in all segments sequentially.
4.4 集群 {#ID_ARC_CLUSTER}
关于架构和集群的基础概念可以阅读官方的一份PPT:Elasticsearch Best Practice Architecture。
主要是了解下Elasticsearch集群的节点分类:

然后看下之前提到过的ELK整体集群拓扑:
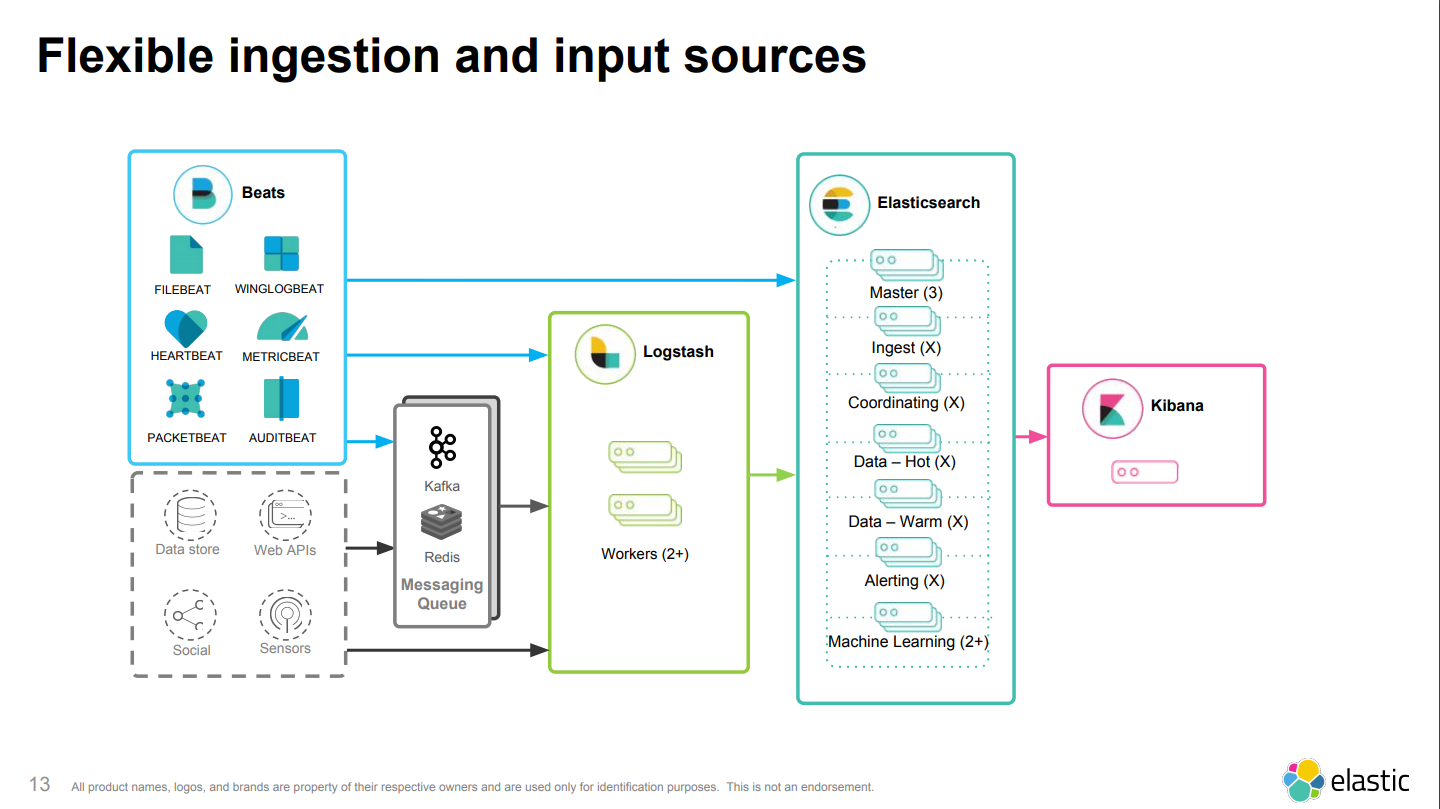
此外推荐一篇:Designing the Perfect Elasticsearch Cluster: the (almost) Definitive Guide。
在官方的文档库中我并没有找到比较新版本的文档有讲解到分布式和高可用之类的架构设计内容,大部分的文档都是各种API和各种细节。在老的版本中倒是找到一点信息:
此外,中文书里的内容也可以阅读:集群内部工作方式,注意这本中文书的版本已经相当老了,里面的内容有部分和现在的版本明显不同。
几点整理:
- replica与数据主节点并不一定是1:1的关系(并不一定一个master拖一个slave这样的设计),这个replica节点数量是可设置的,一个主节点可能有多份完全一致的replica
- 当你的replica设置越多,写入速度就越慢(参与的节点多),主节点写入完毕之后还要让所有的replica写入,全部都完成才会返回客户端完成
- 当你的replica设置越多,查询(读取)速度就越快(参与的节点多)
- 当发生查询请求时,查询请求是会落到所有的shard上的,所以集群shards做的越多,整个集群的查询性能开销就越大,这里就有一个平衡的问题
4.5 监控 & 高可用
4.5.1 监控
对于Elasticsearch的监控,官方有一套解决方案(Elasticsearch算是一个生态了,在上游和下游都有完整的处理)。可以查阅下官方文档:
当然也可以选用Prometheus作为监控:
4.5.2 监控实践
除了官方插件之外,还有更好用的Prometheus集成工具,由justwatch提供的一整套:
- Exporter:
- 代码:justwatchcom/elasticsearch_exporter
- 镜像:justwatch/elasticsearch_exporter
- justwatch/elasticsearch_exporter:1.1.0rc1
- Dashboard:ElasticSearch
只需要在Elasticsearch集群之外启动一个Exporter镜像,并提供Elasticsearch集群的访问地址即可获得所有的metrics,然后在Grafana内导入justwatch提供的Dashboard就可以将数据可视化。整个过程不需要代码介入,直接使用即可,非常完美。
4.5.3 高可用
数据节点数量选择
- Resizing your Elasticsearch Indexes in Production
- Scaling Elasticsearch: Sharding and Availability for Hundreds Of Millions of Documents:这篇当中有一段讲解了
Resharding With Zero Downtime,这是非常有价值的一个topic
可恢复的集群最低配置
- 3 locations to host your nodes. 2 locations to run half of your cluster, and one for the backup master node.
- 3 master nodes. You need an odd number of eligible master nodes to avoid split brains when you lose a whole data center. Put one master node in each location so you hopefully never lose the quorum.
- 2 http nodes, one in each primary data center.
- As many data nodes as you need, split evenly between both main locations.
故障恢复
Elasticsearch在集群中分主节点shard和复制节点replica,当集群的设置足够多(数据冗余充分)的情况下,当某个物理节点不可用时,Elasticsearch会自动进行选举,将丢失的主节点shard的replica节点设置成主节点,并重新对集群进行平衡。举个例子:
事故发生前:
- 一共有3个物理节点
- 一共有3个主节点shard
- 每个主节点shard有2个复制节点replica
- 当前物理节点1是作为整个集群的master节点进行服务的
- 后续事故会发生在物理节点1,这个节点会下线
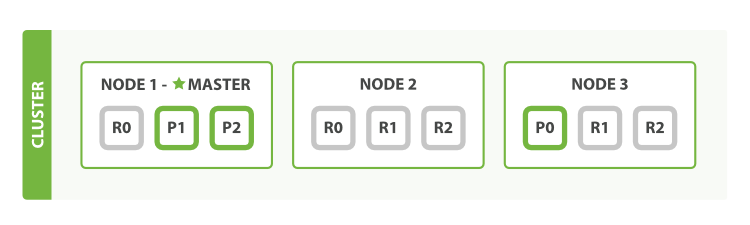
事故发生后:
- master节点下线了,因此集群重新开始选取master节点,设定为物理节点2
- 0号主节点shard(P0)本来就在物理节点3上,因此不受影响
- 1号和2号主节点shard之前在物理节点1上,全部丢失,集群将物理节点2上的2号shard的replica(R2)提升为主节点shard(P2),并将物理节点3上的1号shard的replica(R1)提升为主节点shard(P1)
- 此时所有的主节点shard都已恢复,且各主节点shard都存在一份replica
- 后续集群会继续为各主节点shard复制缺失的一份replica
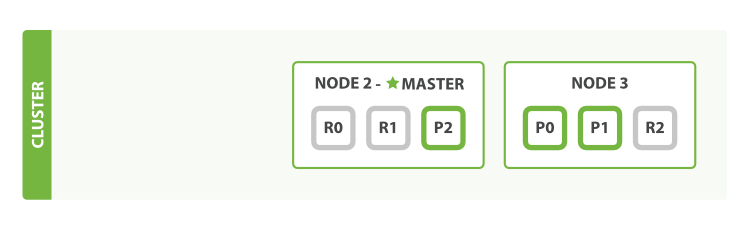
4.6 性能调优
Ebay有一篇非常细节非常棒的设计及性能优化分析博文:Elasticsearch Performance Tuning Practice at eBay。从时间上来看,这篇文章也还算近:2018-01-08。
这篇博文分析了大规模Elasticsearch集群会面临的挑战,以及解决方案,还按实际的应用Scenario进行了问题分析以及给出了解决范例,很棒。
5. Kibana
Kibana这块相对来说比较简单。一些关键文档位置:
5.1 Index Pattern {#ID_INDEX_PATTERN}
在打开Kibana页面进行任何查询和设置之前,必须进行Index Pattern的设置。这是使用的前提。该设置是用来告知Kibana,Elasticsearch集群中的哪些Index是需要进行解析和观察的,作为后续所有查询的数据来源。
官方文档:
官方对于自动化的支持做的不太好,如果需要在Elasticsearch集群启动之后自动化对Kibana内设置Index Pattern的话,该需求是没有官方的解决方案的。找了一圈有一些hack方案,但都不稳定,非常容易因版本更新的原因后续就无法使用了。这方面后面只能说有需要再临时找对应版本的hack。
5.2 使用简介
- 如果只是要简单过滤下数据进行简单的统计或者进行临时的debug日志搜索,那么在
Discover页面直接使用条件搜索过滤即可:Discovering your data - 如果需要对一个常用的搜索或数值结果进行定义,方便后续直接查看,那么可以使用
Visualize页面制作图表,这里的Visualize是和Grafana里的Panel同样的概念:Visualizing your data - 如果需要定义一系列常用的图表进行观察,则可以使用
Dashboard页面进行设置,这里的Dashboard是和Grafana里的Dashboard同样的概念:Displaying your visualizations in a dashboard
一般如果将Elasticsearch作为日志聚合debug工具的话,不需要很复杂的设置,直接使用Discover即可。偶尔会有些例如同时在线或最近请求数量之类的观测需求,那么简单设置下Visualize即可。
5.3 Q&A
6. Filebeat直连Elasticsearch实践
6.1 直连流程
在实际应用的场景中,大部分情况下我们需要的这是将本地日志的内容分类传送到Elasticsearch集群中,按条件定位到不同的索引内。最多也就是对日志里的字段进行一些简单的丰富化或转换。而完成这样的需求其实是不需要Logstash这样的工具,仅使用Filebeat就可以独立完成。这样做的好处是节约了大量系统资源(Golang vs Java),同时还兼具了高可用和性能。
流程也非常简单:
- Filebeat监听本地日志变化
- Filebeat将新产生的日志内容按JSON进行解析
- Filebeat根据日志内的字段内容,进行
processors处理,进行丰富化或进行格式转换 - Filebeat根据根据
Elasticsearch template setting,启用在Elasticsearch集群上设置好的Index Template(只有这步是依赖Elasticsearch集群的,需要预先在Elasticsearch集群中设置好Template) - Filebeat根据设置,将日志传输到Elasticsearch集群中不同的Index里
基本上全部的处理都是在Filebeat里完成了,不需要Ingest Pipeline做什么,更不需要Logstash出马。
实际操作下来,还是有很多细节问题,后面一一细说。
6.2 应用场景
先描述下应用场景,否则后面的一些配置和细节都不好说明。
系统有三个应用程序:
- web
- service
- consumer
每个应用程序都会输出一份日志:
- web:/tmp/logs/app/app.web.stdout.log
- service:/tmp/logs/app/app.service.stdout.log
- consumer:/tmp/logs/app/app.consumer.stdout.log
每个应用除了自身的业务日志之外,也会有一些使用中的组件会在对应的日志内输出内容:
- web:
- web:自身业务日志
- gin:web框架gin的日志
- service:
- service:自身业务日志
- gorm:数据库orm框架的日志
- consumer:
- consumer:自身业务日志
- gorm:数据库orm框架的日志
需求是跟踪、解析这三份日志文件,将输出的日志根据应用以及组件分发到Elasticsearch不同的Index中:
- web:
- web:分发到 dist-web-web-*
- gin:分发到 dist-web-gin-*
- service:
- service:分发到 dist-service-service-*
- gorm:分发到 dist-service-gorm-*
- consumer:
- consumer:分发到 dist-consumer-consumer-*
- gorm:分发到 dist-consumer-gorm-*
解决方案:
- 使用input配置下的fields配置,根据输入的文件,添加自定义字段:
fields.app: web|service|consumer - 使用processors,解析JSON日志内容、字段,添加自定义字段:
fields.module: web|gin|service|consumer|gorm - 根据字段
fields.app``fields.module输出日志到不同的Index:dist-%{[fields.app]}-%{[fields.module]}-%{[agent.version]}-%{+yyyy.MM.dd}
6.3 Index Template {#ID_INDEX_TEMPLATE}
中间还需要补一个Elasticsearch的概念:Index Template。官方文档在:Index Templates,也有一份中文的。
之前在4.2 文档数据库 & 索引已经讲到了,Index即相当于RDBMS里的表名,且在Elasticsearch中是用来进行sharding的重要字段。而同时我们之前也提到过了,在大部分的情况下,Index是自动创建的,按某些格式:dist-%{[fields.app]}-%{[fields.module]}-%{[agent.version]}-%{+yyyy.MM.dd}。所以如果要针对每一个Index进行单独的配置,这基本上是不可能的。在Elasticsearch中,为了应对这样的需求,就有了Index Template这个设置。新创建的Index都会根据名字套用上某个Template(如果有匹配到的话),达到对Index进行设置的目的。
此外,Index Template里还设置了很多细节(这些设置都会在名字匹配的Index上生效):
- Index的shards数量
- Index的replicas数量
- Index如何分词、如何过滤
- Index对应日志中的字段应该怎么解析,分别都是什么类型的字段(如果不设置的话,Elasticsearch会根据第一次出现的值进行猜测,以后将不再更改,除非使用API手动重设)
- 等等
如果某个新创建的Index不符合任何Elasticsearch集群上已知的所有Template,则该Index内的所有设置都会按默认值来。一般来说这种情况下最严重的问题是:该Index将只会存在一个shard,且只会有一份replica。
所以,一般来说都需要在正式使用之前将需要的Index Template创建好,才可能开始向Elasticsearch输入日志,否则创建出来的Index会有问题,至少分片就不对。
额外的资料:
- 有一份中文的博文,讲解的很好,后续可以看下:初探 Elasticsearch Index Template(索引模板)。
- 官方社区有一个讨论帖,里面有comment对如何操作自定义Index Template有比较详细的步骤讲解:Custom filebeat template for JSON log lines。
6.4 Issues
6.4.1 Filebeat字段层级
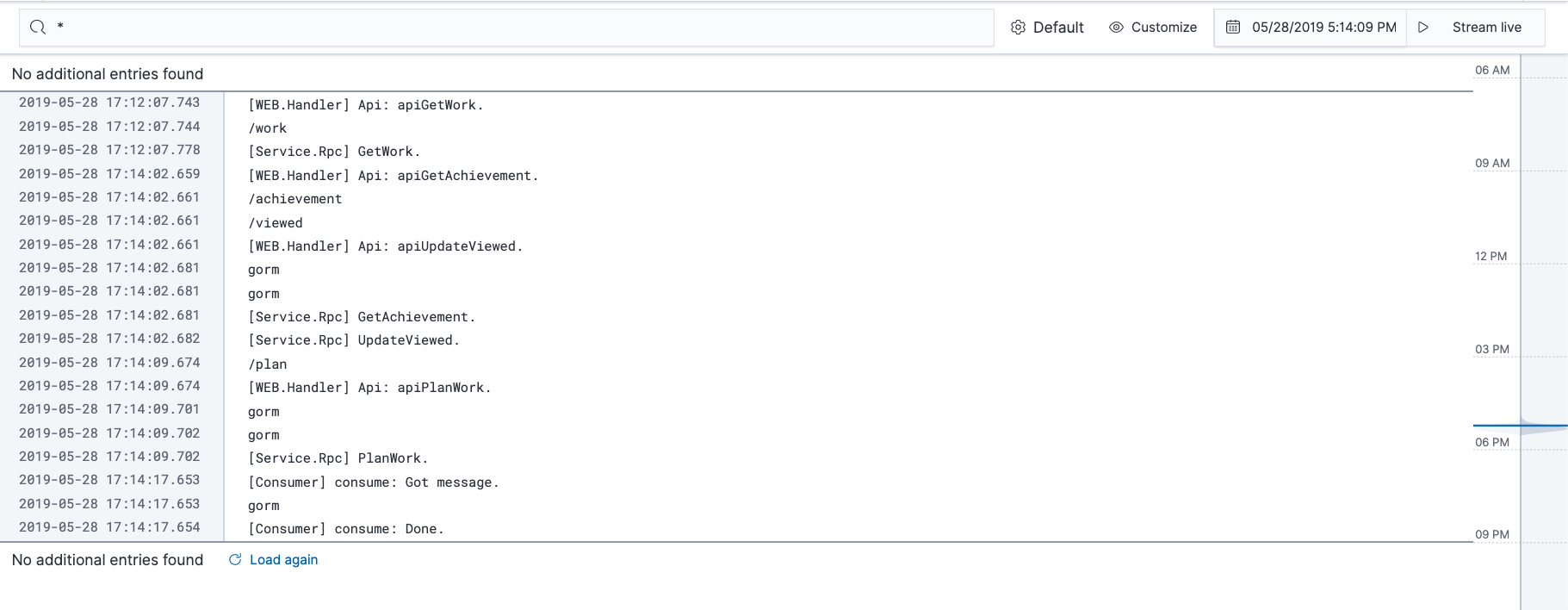
Filebeat默认将日志JSON解析出来的内容放到message字段下,见下图的message字段内容:
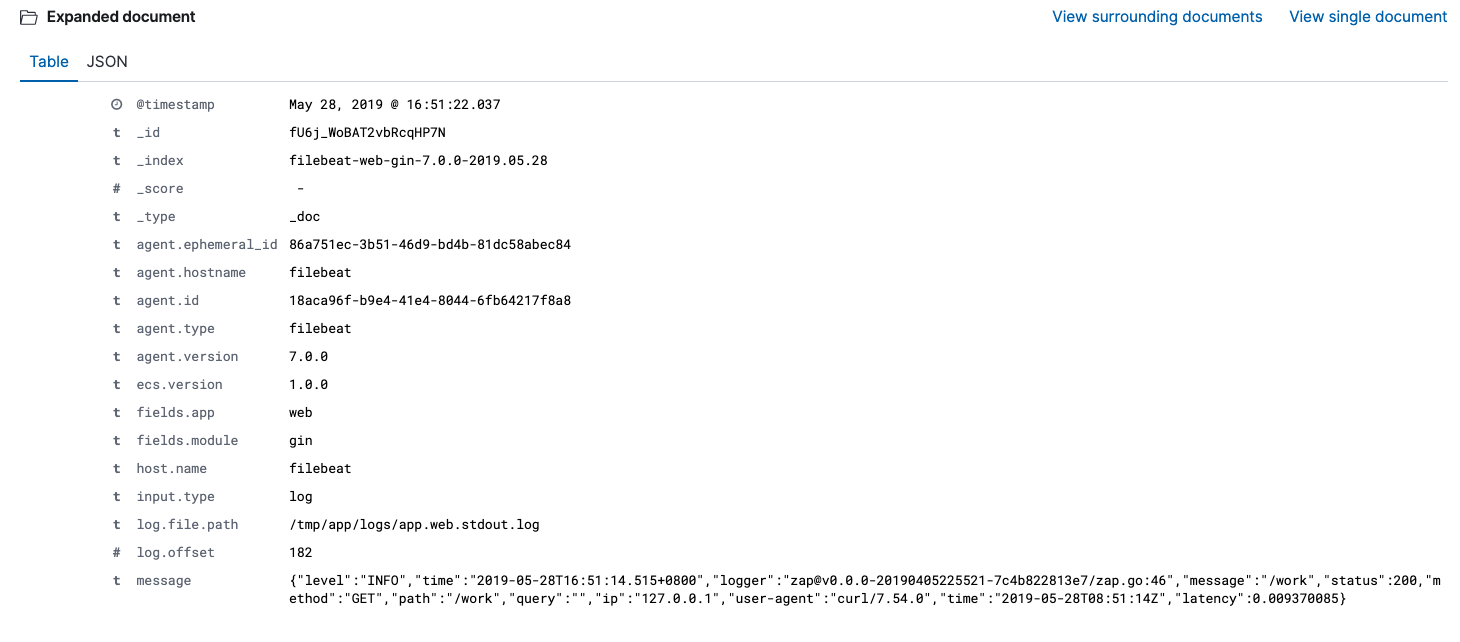
如果不知道这点的话,在使用processors时候会发现设定的条件因字段没有找到而没有被触发。调试的时候会非常痛苦。
这里需要了解filebeat的设置:Log input > json。
有几项配置需要了解下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /...
json.keys_under_root: true
json.overwrite_keys: true
json.message_key: message
...json.keys_under_root: true:将之前存放在message字段里的JSON释放到根节点,效果见下图,可以和上面的图做下比对;一般来说这也是用户希望的效果json.overwrite_keys: true:是否在冲突的时候使用释放出来的字段的值覆盖根目录下同Key的值,一般也需要配置json.message_key: message:这项一般不要改,留默认的message即可,后面会解释原因

如果不配置json.keys_under_root: true也不是不可以,但在查找日志JSON内容的时候就需要到message字段下去查找,而不是根节点。
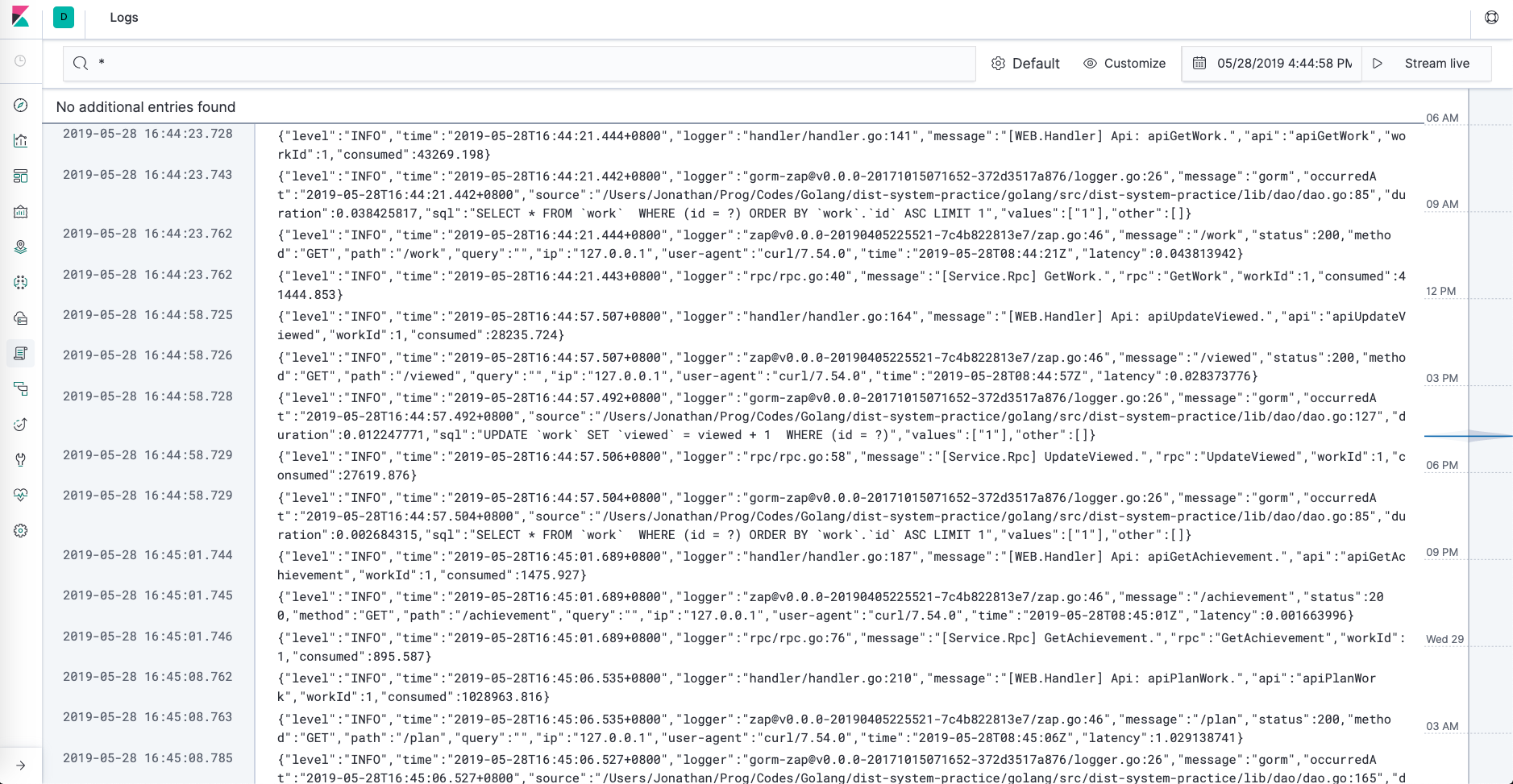
6.4.2 Kibana message字段
Kibana页面上的原始日志页面,显示的是filebeat传输到Elasticsearch日志内容中的message字段内容,且显示的仅只有message字段的内容。并且,当Kibana发现Elasticsearch中存放的日志不存在message字段的时候,还会显示错误:failed to find message。因此之前提到,不要随意更改:json.message_key: message。要更改Kibana的行为也不是不可以,参见:
实际效果可以参见下面两张图的比对,第一张是没有使用json.keys_under_root: true的情况,第二张则是释放之后的情况:
6.4.3 input | processors fields
在filebeat的input配置中,可以根据日志输入向日志内容中添加自定义的字段:
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/app/logs/app.web.stdout.log
fields:
app: web
...在processors配置中,也可以根据条件向日志内容中添加自定义的字段:
processors:
- add_fields:
when:
contains:
message: "WEB.Handler"
fields:
module: "web"
...但有一点需要明确,这些添加的字段,都会存放在根节点下的fields字段里。上面例子里的两个设置,会产生:
- fields.app: web
- fields.module: web
可以看下之前6.4.1图中的字段列表。
6.4.4 Index Template设置 {#ID_FILEBEAT_INDEX_TEMPLATE}
Index Template虽然是在Elasticsearch上创建的(见:6.3 Index Template),但在filebeat端还是需要做设置的。主要是需要在filebeat端加载Elasticsearch上存在的Index Template,然后后续在filebeat向Elasticsearch传输日志的时候,就会应用这些Template。如果配置不正确的话,诸如shards数量之类的配置就会出错、不生效。
- filebeat中关于Index Template的配置项:Load the Elasticsearch index template
- filebeat中如何加载Index Template:Step 4: Load the index template in Elasticsearch
- 此外,该功能一般和输出相关配置有关:Configure the Elasticsearch output > indices
如果不想在Elasticsearch端创建自定义的Index Template,那么可以使用的Template只有一个,就是filebeat默认的:filebeat-%{[agent.version]}-%{+yyyy.MM.dd},在当前的版本下就是:filebeat-7.0.0-2019-05-29。
该默认的Template在Elastcsearch上的配置可以通过API Getting templates 进行观察:
"filebeat-7.0.0": {
"order": 1,
"index_patterns": [
"filebeat-7.0.0-*"
],
"settings": {
"index": {
"lifecycle": {
"name": "filebeat-7.0.0",
"rollover_alias": "filebeat-7.0.0"
},
"mapping": {
"total_fields": {
"limit": "10000"
}
},
"refresh_interval": "5s",
"number_of_shards": "3",
...可以看到,该Template的名字匹配pattern是:filebeat-7.0.0-*,所以如果要利用这个默认的Template的话,名字一定不能搞错。我之前做实验的时候使用过:
- filebeat-web-web-7.0.0-*
- filebeat-web-gin-7.0.0-*
- …
之类的,就因为名字不匹配导致没有套用上这个Template,最后shards数量之类的就全错了。
6.4.5 切片数量
查看集群Index切片状态,可以通过API cat shards。
范例集群的切片设置为:主节点数量3,replica数量1。也就是说一个Index的切片总数为:primary * (1 + replica) = 6。公式括号中的1就是primary,每一份切片只会有一个primary。
$ curl -X GET "http://127.0.0.1:9201/_cat/shards"
dist-consumer-gorm-7.0.0-2019.05.29 2 p STARTED 0 230b 172.20.0.4 es_2
dist-consumer-gorm-7.0.0-2019.05.29 2 r STARTED 0 230b 172.20.0.2 es_3
dist-consumer-gorm-7.0.0-2019.05.29 1 r STARTED 0 230b 172.20.0.4 es_2
dist-consumer-gorm-7.0.0-2019.05.29 1 p STARTED 0 230b 172.20.0.3 es_1
dist-consumer-gorm-7.0.0-2019.05.29 0 p STARTED 1 17.2kb 172.20.0.2 es_3
dist-consumer-gorm-7.0.0-2019.05.29 0 r STARTED 1 17.2kb 172.20.0.3 es_1
dist-web-gin-7.0.0-2019.05.29 2 r STARTED 0 230b 172.20.0.4 es_2
dist-web-gin-7.0.0-2019.05.29 2 p STARTED 0 230b 172.20.0.2 es_3
dist-web-gin-7.0.0-2019.05.29 1 r STARTED 2 32.3kb 172.20.0.4 es_2
dist-web-gin-7.0.0-2019.05.29 1 p STARTED 2 32.3kb 172.20.0.3 es_1
dist-web-gin-7.0.0-2019.05.29 0 p STARTED 2 32.3kb 172.20.0.2 es_3
dist-web-gin-7.0.0-2019.05.29 0 r STARTED 2 32.3kb 172.20.0.3 es_1
dist-service-gorm-7.0.0-2019.05.29 2 p STARTED 4 33.4kb 172.20.0.2 es_3
dist-service-gorm-7.0.0-2019.05.29 2 r STARTED 4 33.4kb 172.20.0.3 es_1
dist-service-gorm-7.0.0-2019.05.29 1 r STARTED 1 16.6kb 172.20.0.4 es_2
dist-service-gorm-7.0.0-2019.05.29 1 p STARTED 1 16.6kb 172.20.0.3 es_1
dist-service-gorm-7.0.0-2019.05.29 0 p STARTED 0 230b 172.20.0.4 es_2
dist-service-gorm-7.0.0-2019.05.29 0 r STARTED 0 230b 172.20.0.2 es_3
dist-consumer-consumer-7.0.0-2019.05.29 2 p STARTED 1 14.6kb 172.20.0.4 es_2
dist-consumer-consumer-7.0.0-2019.05.29 2 r STARTED 1 14.6kb 172.20.0.2 es_3
dist-consumer-consumer-7.0.0-2019.05.29 1 r STARTED 0 230b 172.20.0.2 es_3
dist-consumer-consumer-7.0.0-2019.05.29 1 p STARTED 0 230b 172.20.0.3 es_1
dist-consumer-consumer-7.0.0-2019.05.29 0 p STARTED 1 14.6kb 172.20.0.4 es_2
dist-consumer-consumer-7.0.0-2019.05.29 0 r STARTED 1 14.6kb 172.20.0.3 es_1
.kibana_1 0 r STARTED 6 50.2kb 172.20.0.4 es_2
.kibana_1 0 p STARTED 6 50.2kb 172.20.0.3 es_1
dist-service-service-7.0.0-2019.05.29 2 r STARTED 0 230b 172.20.0.4 es_2
dist-service-service-7.0.0-2019.05.29 2 p STARTED 0 230b 172.20.0.2 es_3
dist-service-service-7.0.0-2019.05.29 1 r STARTED 3 28.2kb 172.20.0.2 es_3
dist-service-service-7.0.0-2019.05.29 1 p STARTED 3 14.9kb 172.20.0.3 es_1
dist-service-service-7.0.0-2019.05.29 0 p STARTED 1 13.9kb 172.20.0.4 es_2
dist-service-service-7.0.0-2019.05.29 0 r STARTED 1 13.9kb 172.20.0.3 es_1
.kibana_task_manager 0 p STARTED 2 45.4kb 172.20.0.4 es_2
.kibana_task_manager 0 r STARTED 2 45.4kb 172.20.0.2 es_3
dist-web-web-7.0.0-2019.05.29 2 p STARTED 2 27.9kb 172.20.0.2 es_3
dist-web-web-7.0.0-2019.05.29 2 r STARTED 2 27.9kb 172.20.0.3 es_1
dist-web-web-7.0.0-2019.05.29 1 r STARTED 1 14kb 172.20.0.4 es_2
dist-web-web-7.0.0-2019.05.29 1 p STARTED 1 14kb 172.20.0.3 es_1
dist-web-web-7.0.0-2019.05.29 0 p STARTED 1 14kb 172.20.0.4 es_2
dist-web-web-7.0.0-2019.05.29 0 r STARTED 1 14kb 172.20.0.2 es_3
filebeat-7.0.0-2019.05.29-000001 2 p STARTED 0 230b 172.20.0.4 es_2
filebeat-7.0.0-2019.05.29-000001 2 r STARTED 0 230b 172.20.0.2 es_3
filebeat-7.0.0-2019.05.29-000001 1 r STARTED 0 230b 172.20.0.2 es_3
filebeat-7.0.0-2019.05.29-000001 1 p STARTED 0 230b 172.20.0.3 es_1
filebeat-7.0.0-2019.05.29-000001 0 p STARTED 0 230b 172.20.0.4 es_2
filebeat-7.0.0-2019.05.29-000001 0 r STARTED 0 230b 172.20.0.3 es_1输出的内容有几列,这里解释下含义:
Index名:dist-consumer-gorm-7.0.0-2019.05.29节点编号:切片在当前Index的切片组中的编号,从0开始,一个primary占用一个编号,所有该primary的从属replicas和primary共享同一个编号节点类型:只有p和r,表示是primary还是replica节点状态:正常状态为STARTED,启动中为INITIALIZING,错误状态为UNASSIGNED;unassigned相关参见:Reasons for unassigned shard文档数量:存储在该节点内的文档数量节点容量:节点占用的磁盘容量节点IP:节点的IP地址节点名:节点在Elasticsearch集群中的名字
6.4.6 Kibana @timestamp
Filebeat向Elasticsearch传输的日志内容会添加一个字段:@timestamp。而Kibana在设置Index Pattern(5.1 Index Pattern)的时候,强制需要选择一项日志内的时间字段作为后续时间相关过滤的指标。如果用户没有自己的时间字段的话,一般都会选择@timestamp字段,因为该段总是存在的。
不过这里有一项需要注意:
@timestamp 是日志被filebeat处理的时间点,而不是日志发生的时间点。一般来说这两者可以混用,但在日志有堆积,处理比较慢的情况下,就不合适了。千万需要小心,一般来说尽量选择业务日志自带的时间字段,就不会有问题了。
6.4.7 Elasticsearch 预创建数据
一般来说,在Elasticsearch启动的时候都会有创建一些预设配置的需求,特别是在docker中运行的时候,因为docker本来就具有高度自动化的特征,也就格外需要这样的预设数据。这方面只能说官方仍旧没有提供非常完备的支持,只能自行处理:
- Best practice for creating an index when an ES docker container starts
- How to add an elasticsearch index during docker build
7. 实践范例
和之前做Prometheus实验的时候一样,因为需要把握一些细节,所以实验使用的还是下载下来的Elasticsearch、Kibana以及Filebeat。作为配角的Nginx使用的则是镜像版本。
范例代码可以在Github查看:dist-system-practice/experiment/elasticsearch/。
这则例子非常简单,基本上没有涉及任何比较核心的使用,粗略看下启动还是可以的。
8. Docker集群部署
仍旧是使用docker-compose进行群组的编辑和启动,可运行范例可以查看:dist-system-practice/conf/dev/elk-cluster.yaml。
启动脚本:dist-system-practice/bash/dev/docker_elasticsearch.sh。
下面会根据职责一一解析配置文件。
8.1 Elasticsearch配置 {#ID_ES_CONFIG}
elk-cluster.yaml
x-es-environment-defaults:
C1: &DISCOVERY_SEED_HOSTS "discovery.seed_hosts=es_1:9300,es_2:9300,es_3:9300" # 集群中的所有可用节点,这个配置中需要完整给出节点的HOST和PORT
C2: &CLUSTER_INITIAL_MASTER_NODES "cluster.initial_master_nodes=es_1,es_2,es_3" # 集群初始化的master节点,这个配置中只需要给节点名,即 node.name=es_1 里面设置的名字
C4: &ES_JAVA_OPTS "ES_JAVA_OPTS=\
-Xms256m \
-Xmx256m \
"
x-es-ulimit-defaults: &ES_ULIMIT_DEFAULTS
nproc: 65535
nofile:
soft: 65535
hard: 65535
memlock:
soft: -1
hard: -1
x-es-logging-defaults: &ES_LOGGING_DEFAULTS
driver: "json-file"
options:
max-size: "512m"
networks:
net:
driver: "bridge"
volumes:
es_vol_1_logs:
driver: "local"
es_vol_1_data:
driver: "local"
services:
es_1:
image: "elasticsearch:7.0.0"
container_name: "es_1"
hostname: "es_1"
volumes:
- es_vol_1_data:/usr/share/elasticsearch/data
- es_vol_1_logs:/usr/share/elasticsearch/logs
- /private/tmp/elasticsearch.yaml:/usr/share/elasticsearch/config/elasticsearch.yml
networks:
- "net"
ports:
- "9201:9201" # 该PORT是给外部访问使用的,比如Kibana、Filebeat,以及客户端查询API
expose:
- "9300" # 该PORT是给集群内部流量使用的,所以只要expose即可
restart: "always"
logging:
<<: *ES_LOGGING_DEFAULTS
environment:
- node.name=es_1 # 节点名必须设置且不可重复
- http.port=9201 # 这个PORT同上
- node.master=true # 如果需要该节点作为master角色提供服务,则这里设置成true
- node.data=true # 如果需要该节点作为数据节点提供服务(数据存储),则这里设置成true
- *DISCOVERY_SEED_HOSTS
- *CLUSTER_INITIAL_MASTER_NODES
- *ES_JAVA_OPTS
ulimits:
<<: *ES_ULIMIT_DEFAULTSelasticsearch.yaml
cluster.name: es_cluster
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
transport.tcp.port: 9300相关文档:
- 官方文档及范例配置文件:Install Elasticsearch with Docker
- 理解Elasticsearch的集群发现:Discovery
- 全局变量配置的使用:Environment variable substitution
- 同上,不同的做法:Configuring Elasticsearch with Docker
- 一些比较常见的问题:使用ElasticSearch踩过的坑
- 一个非常完整的搭建例子:ELK Stack+Beats 搭建分布式日志平台
- 大杂烩:Elasticsearch安装配置
- 带说明的非docker安装:Creating an Elasticsearch Cluster: Getting Started
8.1.1 环境变量配置
Elasticsearch的环境变量配置要求使用配置文件中的配置项字符串,完全不用改动,全部都是小写,然后使用=连接配置项的值。此外需要注意,数组的配置和配置文件中有所不同,直接使用以,分隔的字符串即可:discovery.seed_hosts=es_1:9300,es_2:9300,es_3:9300。
environment:
- node.name=es_1
- http.port=9201
- node.master=true
- node.data=true
- ...8.1.2 多节点配置的共享
Elasticsearch docker compose的配置中,需要把environment配置成数组,而YAML则恰恰不支持数组的Anchor Merge。这是YAML的一个功能性问题,不支持Array的平铺Merge:Merge arrays #35。社区的方案一般都需要在原生的YAML之外,再使用工具把嵌套的Array整平:Is there a way to alias/anchor an array in YAML?,这就在我的接受范围之外了,我不希望使用任何第三方工具来修改yaml文件。
最后方案为:
- 把不怎么需要在运行时修改的共通变量写入配置文件
- 使用bind mount的方法加载配置文件到容器里
- 在yaml中设置变量
- 在多节点中使用变量,至少里面的值只需要改一个地方就可以生效了
8.1.3 集群发现相关配置
官方文档:Important discovery and cluster formation settings。
集群发现主要依赖两项配置:
- discovery.seed_hosts=es_1:9300,es_2:9300,es_3:9300
- cluster.initial_master_nodes=es_1,es_2,es_3
discovery.seed_hosts用来告知Elasticsearch组成集群的所有节点都是谁,分别HOST和PORT是什么。无论是否是master节点,或者是否仅仅只是data节点,都需要列在这个选项中,告知给Elasticsearch。这个选项里的配置是常规的host:port。
cluster.initial_master_nodes用来告知Elasticsearch,集群启动的时候初期可用的master节点是哪几个,之后Elasticsearch会从这些节点中选出master节点。列在这个配置中的节点,其node.master=true必须为true。
然后,这个配置有个坑,非常非常坑,这个配置中的所有字符串,列的都是节点的名字,即必须和node.name=es_1里的名字一致,不需要配置成host:port,只需要node_name。官方文档中的例子因为是docker,所以节点的名字和docker network中的container名字是一致的,而且官方的例子用的都是默认port,所有的port都没写,所以我一开始误认为这个选项里的配置也是host:port,然后各种无法组成集群。而且Elasticsearch针对这种错误给的错误信息非常暧昧,完全找不到有用的信息。最后找了半天才在官方论坛的一个帖子里找到线索。我填了这个坑之后貌似官方文档就更新了。
Elastic Search 7 unable to bootstrap the cluster due to master not discovered yet(这个comment离我找到它只隔了3天,超级新的问题):
Remove the port from the cluster.initial_master_nodes setting, and it will work. We have updated the docs recently to make it clearer that either node name, or ip/port is to be used. Node name/port is not a valid combination.
It is intentional. This setting does not denote a hostname, but the node name or the advertised publish address. In particular, it is not an address that is resolved or actively connected to. The discovery.seed_hosts setting is used for that. The cluster.initial_master_nodes setting is used to determine the identities of the subset of master-eligible nodes that participate in the bootstrapping process after discovery.seed_hosts has established a connection to the nodes.
UPDATE
在后续的实践中遇到了新问题,之前测试因为都一直使用一个物理机,并将所有的es节点都部署在同一个docker network下,因此没有发现问题。
问题描述:如果将不同的容器放入并非同一个而是分开的单独network中,集群的组建就不能依赖docker network当中内部的host,而是需要手动设定,否则集群无法组建起来。
这个问题和kafka集群的INSIDE、OUTSIDE设置,需要配置不同的HOST是一样的道理。为了让es集群各节点能在隔离的网络下互相访问,需要在设置中指明内部流量应该通过什么地址进行相互发现。上文中关于集群组建的相关配置一个都不能少,也不需要改动,这里需要做的配置改动是引进一个新的配置项:network.publish_host。
When running Elasticsearch, you will need to ensure it publishes to an IP address that is reachable from outside the container; this can be configured via the setting network.publish_host.
这个配置项配置为:${物理主机HOST/IP}:${内部流量PORT}即可,e.g 192.168.3.111:9300。这样集群里的各节点就可以相互发现并组成集群了。
8.2 Kibana配置
services:
kibana:
image: "kibana:7.0.0"
container_name: "kibana"
hostname: "kibana"
depends_on:
- "es_1"
- "es_2"
- "es_3"
networks:
- "net"
ports:
- "5601:5601"
restart: "always"
logging:
<<: *ES_LOGGING_DEFAULTS
environment:
- SERVER_PORT=5601
- SERVER_HOST=0.0.0.0
- SERVER_NAME=es_cluster
- ELASTICSEARCH_HOSTS=["http://es_1:9201"]
- KIBANA_INDEX=.kibana
- DIBANA_DEFAULTAPPID=home
- ELASTICSEARCH_PINGTIMEOUT=1500
- ELASTICSEARCH_REQUESTTIMEOUT=10000
- ELASTICSEARCH_LOGQUERIES=false相关文档:
Kibana环境变量的配置和Elasticsearch不一致:
- Elasticsearch使用的是数组,常量的键使用的直接是配置文件中的键,不需要转大写和下划线
- Kibana使用的是数组,常量的键使用的是配置文件中的键转大写,且将点转换成下划线
当前版本有一个配置项相关非常严重的BUG:Kibana fails to validate config if elasticsearch.hosts is not a string #32303。
简单来说就是ELASTICSEARCH_HOSTS这项配置,如果写成下面的任何一种,都不正确,Kibana会报错告知找不到Elasticsearch集群:
ELASTICSEARCH_HOSTS:
- http://es_1:9201
- http://es_2:9202
- http://es_3:9203
ELASTICSEARCH_HOSTS=["http://es_1:9201","http://es_2:9202","http://es_3:9203"]
ELASTICSEARCH_HOSTS=es_1:9201,es_2:9202,es_3:9203虽然上面的写法其实理论上来说都是合法的,但现在就是会出错。现在唯一的写法是:ELASTICSEARCH_HOSTS=["http://es_1:9201"]。写成数组格式,但里面只能放一个节点,这样就不会出错。
8.3 Filebeat配置
elk-cluster.yaml
services:
filebeat:
image: "elastic/filebeat:7.0.0"
container_name: "filebeat"
hostname: "filebeat"
depends_on:
- "es_1"
- "es_2"
- "es_3"
networks:
- "net"
volumes:
- /private/tmp/filebeat.yaml:/usr/share/filebeat/filebeat.yml
- /private/tmp/logs/app:/tmp/app/logs
restart: "always"
logging:
<<: *ES_LOGGING_DEFAULTS
environment:
- ES_HOSTS=es_1:9200,es_2:9200,es_3:9200
- LOGGING_LEVEL=debug # error, warning, info, debug
- NUM_OF_OUTPUT_WORKERS=9 # workers会均匀分配到node:如果有3个ES的node,那么每个node会分到3个workers
- NUM_OF_SHARDS=3
- NUM_OF_REPLICAS=1filebeat.yaml
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/app/logs/app.web.stdout.log
json.keys_under_root: true # 释放日志JSON到根节点
fields:
app: web # 根据日志文件,添加不同的app字段值,后续会使用该值进行不同的Index分发
- type: log
enabled: true
paths:
- /tmp/app/logs/app.service.stdout.log
json.keys_under_root: true
fields:
app: service
- type: log
enabled: true
paths:
- /tmp/app/logs/app.consumer.stdout.log
json.keys_under_root: true
fields:
app: consumer
logging.level: '${LOGGING_LEVEL}'
logging.selectors: ["*"]
processors:
- add_fields:
when:
contains:
message: "WEB.Handler" # 根据日志内容,进行条件匹配
fields:
module: "web" # 根据不同的匹配,添加不同的module字段值,后续会使用该值进行不同的Index分发
- add_fields:
when:
contains:
logger: "7c4b822813e7" # "logger":"[email protected]/zap.go:46"
fields:
module: "gin"
- add_fields:
when:
contains:
message: "gorm"
fields:
module: "gorm"
- add_fields:
when:
contains:
message: "Service.Rpc"
fields:
module: "service"
- add_fields:
when:
contains:
message: "Consumer"
fields:
module: "consumer"
setup.template.name: "dist" # 启用的Elasticsearch Index Template,注意这个Template必须在Elasticsearch中存在
setup.template.pattern: "dist-*" # Index名字匹配模式
setup.template.settings:
index.number_of_shards: '${NUM_OF_SHARDS}'
index.number_of_replicas: '${NUM_OF_REPLICAS}'
output.elasticsearch:
hosts: '${ES_HOSTS}'
worker: '${NUM_OF_OUTPUT_WORKERS}'
indices: # 根据之前添加的字段,决定应该发送日志到什么Index
- index: "dist-%{[fields.app]}-%{[fields.module]}-%{[agent.version]}-%{+yyyy.MM.dd}" # 注意这里使用到的Index名字需要匹配Index Templateelk-index-template.json
{
"order": 1,
"index_patterns": [
"dist-*"
],
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "5s"
}
}
}相关文档:
Filebeat的环境变量配置和Kibana还有Elasticsearch都不一致,明明是一家公司的三个组件,居然相互之间的做法各不相同,也是服了。Filebeat的做法是在启动时设置环境变量,但这个环境变量不会自动转换并覆盖配置文件中的值,而是需要在配置文件中使用${ENV_KEY}这样的方法来使用环境变量的值。
此外,关于非常重要的Index Template设置,参见:6.4.4 Index Template设置。
9. TODO
- Elasticsearch集群及一些基本观察用的API熟悉
- Elasticsearch JVM相关参数和实践研究
- Elasticsearch reshard的策略,最佳实践
- Elasticsearch reshard时候的CPU、磁盘、内存,还有特别是网络的影响
- Elasticsearch reshard在各种集群规模下的耗时
- Elasticsearch的性能指标研究
- Elasticsearch性能测试
- Kibana使用深入
- 添加Logstash部分内容,这块由于时间问题暂时不准备展开
资料
链接
- 5 Logstash Alternatives
- StevenACoffman/fluent-filebeat-comparison.md
- Fluentd retains excessive amounts of memory after handling traffic peaks #1657
- Filebeat 模块与配置
- Operating Elasticsearch for Fun and Profit
- Elasticsearch 权威指南(中文版)
- Lucene 查询原理及解析
- What is the difference between Lucene and Elasticsearch
- Designing the Perfect Elasticsearch Cluster: the (almost) Definitive Guide
- 集群内部工作方式
- Prometheus Exporter Plugin for Elasticsearch
- Resizing your Elasticsearch Indexes in Production
- Scaling Elasticsearch: Sharding and Availability for Hundreds Of Millions of Documents
- Elasticsearch Performance Tuning Practice at eBay
- Index pattern creation API #3709
- What’s the difference between the ‘field’ and ‘field.keyword’ fields in Kibana?
- 初探 Elasticsearch Index Template(索引模板)
- Custom filebeat template for JSON log lines
- Log UI failed to format message from
- [InfraOps] Update docs with data source configuration
- Best practice for creating an index when an ES docker container starts
- How to add an elasticsearch index during docker build
- 使用ElasticSearch踩过的坑
- ELK Stack+Beats 搭建分布式日志平台
- Elasticsearch安装配置
- Creating an Elasticsearch Cluster: Getting Started
- Merge arrays #35
- Is there a way to alias/anchor an array in YAML?
- Elastic Search 7 unable to bootstrap the cluster due to master not discovered yet
- Kibana fails to validate config if elasticsearch.hosts is not a string #32303
- Optimizing Elasticsearch: How Many Shards per Index?
EOF